
复现论文《SPIKING CONVOLUTIONAL NEURAL NETWORKS FOR TEXT CLASSIFICATION》
前言
记录一下复现论文《SPIKING CONVOLUTIONAL NEURAL NETWORKS FOR TEXT CLASSIFICATION》的过程,以免就调包感觉自己什么也没干。不建议一步一步跟着我的步骤做,这个是实况,建议跳着看看再参考着做
论文概况
借助工具,大概对此篇的论文的认识如下
这篇文章探讨了使用脉冲神经网络(SNN)进行自然语言处理任务的可行性,以实现比深度神经网络更节能的效果。虽然SNN已被证明在视觉任务中可产生具有竞争力的结果,但由于以脉冲形式表示单词和处理变长文本的困难,对于它们在自然语言处理(NLP)任务中的有效性的研究还很少。作者提出了一种“转换+微调”的两步法来训练SNN进行文本分类,并提出了一种编码预训练词嵌入为脉冲训练的有效方法,使SNN能够利用来自大量文本数据的词嵌入。实证结果表明,经过所提出的方法训练的SNN在能源消耗更少的情况下能够实现与其DNN同行竞争的结果,并且它们也更具对抗性。该研究是在英语和中文语言的文本分类任务中展示SNN有效性的首批研究之一,并突显了转换方法和微调阶段中的代用梯度作为该领域的一个关键贡献。 |
在论文的末尾,找到作者开源的代码,并将其下载下来
弯路1
然后用Pycharm打开刚开作者的项目,找到md文档,点击Install Requirements旁边的绿色箭头一键安装环境

经过一段时间,大部分都安装好了,但是有些还是出现了类似如下的报错

这时候需要分别查看requirements.txt和textattack_r.txt文件里,查看有哪些包没有装好
首先把Pycharm的环境切换到snn

查看requirements.txt文件

纳尼?!为什么显示一个都没装,那么刚刚的东西都装哪了
重新检查了一下刚刚命令行的代码,发现了问题,在脚本里使用conda activate是不会生效的

按照上面的建议,修改一下切换环境的代码,然后将第一句注销了
conda create -n snn python=3.7 |
再次点击旁边的绿色小箭头!

emmmmm他演我!看来还是自己老老实实用命令行吧

而且环境里的Python文件都有问题了!
……
……
重头开始吧
先把环境删了重新装一下
conda remove -n snn --all |
安装环境
重装环境
conda create -n snn python=3.7 |
然后Pycharm重新加载一下环境,使用命令行进入到项目的路径
cd /d D:\code\SNN |
安装环境
pip install -r requirements.txt |

走起!

找不见文件?!检查了一下,发现是作者是文件名和代码里的名字对不上(少了一个i)
把其中一句改一下
pip install -r requrements.txt |
再跑一次!

很好,没有报错!再继续安装另一个文件里的包

根据提示,只有 pycld2这个包没有安装成功
重新单独装一下试试
pip install pycld2 |

还是报错,这次发现了原因,是缺少某个C++的库,点进去提供的链接进行下载
选择如下模块进行安装(建议装在除C盘外的盘,占用

经过大概20多分钟,安装完毕,重启,然后再次安装那个包

啊嘞,还报错!
通过搜索,看到了一个解决方案。首先进去这个网站下载需要安装的包,由于当前环境是Python3.7的,所以下载如下的包

下载完成后,使用如下命令进行安装:
pip install .whl文件的绝对路径 |
例如我的命令
pip install G:\Download\Chrome\pycld2-0.41-cp37-cp37m-win_amd64.whl |
走起!

nice,这下包就全部安装完毕了,可以试试能不能跑起来了
下载数据库ChnSenti

当我翻到最后时,发现居然要自己准备数据集!!!
让我翻一下论文康康他们用的什么数据集,发现他们中文数据集用的是ChnSenti和Waimai,我挑了一个ChnSenti数据集
网上搜索一下ChnSenti数据集的下载地址,找到一个github的地址
将下载的ChnSentiCorp_htl_all.csv文件放在项目中(新建一个名为datasets的文件夹)

然后应该就是找找从哪调用这个数据集,改一下路径什么的了
安装环境DLC
ちょっと待って,好像还有包没有装完

鼠标右键一键安装一下(好像要一个什么插件,根据Pycharm的提示安装一下就行)
然后就可以摸摸鱼了
经过了一个多小时的等待,安装的差不多了

把剩下的包再装一下
pip install bert-score==0.3.5 |
安装完毕后,就会显示浅色的波浪线了

接下来应该就是跑程序了,我需要跑的是一个中文数据集
根据作者的md文件
Shift Pre-trained Word Embeddings to [0, 1]
cd data_preprocess |
找到项目根目录\data_preprocess\chinese_tensor_encoder.py

这里应该需要把地址和数据集(也改成txt格式的)改一下
先换格式

然后改一下地址
datafile_path="../datasets/chnsenti_test.txt" |
先跑一下试试

重装numpy
大概意思应该是我numpy这个包有问题,康康自己是装的是什么版本的
pip list |
然后Ctrl+Shift+F搜索一下numpy,发现我的版本是1.21.6,盲猜是不是有点高了

根据之前的经验,可能是TensorFlow和numpy的版本不适配导致的
于是查了一下,果然不匹配,我的TensorFlow版本是1.14.0

于是重装一下numpy
pip install -U numpy==1.16.0 |

然后跳出来一片红……我的基金要是这样红该有多好
研究一下,装一下版本为1.17.3的就可以全解决,再试一下
pip install -U numpy==1.17.3 |

还有一个问题,是torchvision不和torch版本不匹配,重新安装一下torch吧,(我记得他会自动卸载之前的版本)
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 |
安装完以后,在试一次!

又双叒叕报错了,这次应该是pyarrow这个包有问题,试试重装?
pip install -U pyarrow |
再跑一次试试

好消息,刚才那个错是没有了。看前面几行,好像是numpy装了两个版本吗,查看一下
pip list |

只有一个啊,是不是之前操作失误,把包全装在base环境里导致的
切换到base环境删除numpy(这个需要使用管理员运行prompt)
pip uninstall numpy |

再跑一次试试
好吧还是刚刚那个问题,要不这次直接物理删除试试\doge,找到他说的地方,删除其中一个文件

在跑一次康康有没有前面的报错了(删除要关闭Pycharm,否则会提示文件被占用)

啊这,这是删除崩了吗,那就重装一下吧,把剩下的直接物理删除完

重新安装一下(复制一下上面的代码
pip install -U numpy==1.17.3 |

怎么感觉自己越走越远了,试试他给我的建议
pip install --force-reinstall --no-deps numpy==1.21.6 |

淦,还不行,等等,我可以从回收站恢复!还可以挽救。
恢复完毕后,再跑一下看看

又回到了这个熟悉的报错,那就先解决下面的问题吧,感觉是什么xxhash的包有问题
重新安装一下试试
pip install -U xxhash |

看来刚刚一番折腾,还得把numpy这个包重装一下
pip install -U numpy==1.17.3 |

啊?我康康能不能先卸载了

也不太行,查了一下网上的强制升级试试?
pip install numpy --ignore-installed numpy |

nice,装好了,那再重装到1.17.3版本试试
pip install -U numpy==1.17.3 |

回来了,都回来了!跑一下试试
解决报错OSError: [WinError 126]

又换错了…但是前面的冲突居然没有了耶
查了一下网上这个错最好还是重装
那就试试重装nltk这个包吧
pip uninstall nltk |
再跑试试。好吧还是上面那个错。网上看了一个博客的解决方法,打算试试

但是这个错我感觉还是nltk这个包的问题啊
查一下作者用的版本

这也太痛了,那么就查一下nltk关于OSError: [WinError 126]这个错的方向吧
果不其然搜到了

照着上面的解决方案做一下

但是还是有戏的,安装完毕

再….跑一次试试吧

???为什么。网上搜了一圈也没有很合适的,问问万能的chatGPT吧

我盲猜可能是因为第三条,安装一下试试,由于找不见他说的Microsoft Visual C++ Redistributable for Visual Studio,我直接装了一个IDE,(这总可以包含了吧)

跑一下试试

oh no!我不信了!B站找到了一个下载方式,把文件下载下来如下:

运行一下.bat文件试试

然后重启一下试试,然后跑一下

所以可能就不是少装C++库的问题吧,把nltk重装了试试吧
pip uninstall nltk |
用网上验证成功安装的方法检测一下:

from nltk.book import * |

这应该是成功安装了,再跑试试

卡住了啊!难道是这个版本太新了?可是也不知道作者的版本是多少啊emm。全局搜一下康康能不能有什么线索
最后也没找到emm,问问chatGPT 4.0的试试吧……
出现这个错误的原因可能是nltk库所依赖的某些模块或动态链接库在你的系统中找不到。为了帮助你解决这个问题,请按照以下步骤操作: |
感觉完全没用呀,要不我试试把x86的Microsoft Visual C++ 2015-2019 Redistributable卸载了?有没有可能和x64版本的相互影响?

卸载完后,在运行试试?
太离谱了,还是上面的错!又看了几个博客,好像意思是可能是依赖缺少的问题,他们推荐用Dependency Walker这个软件下一下组件

我下载的是这个,根据网上说明,只要找到dll或者exe文件就可以了
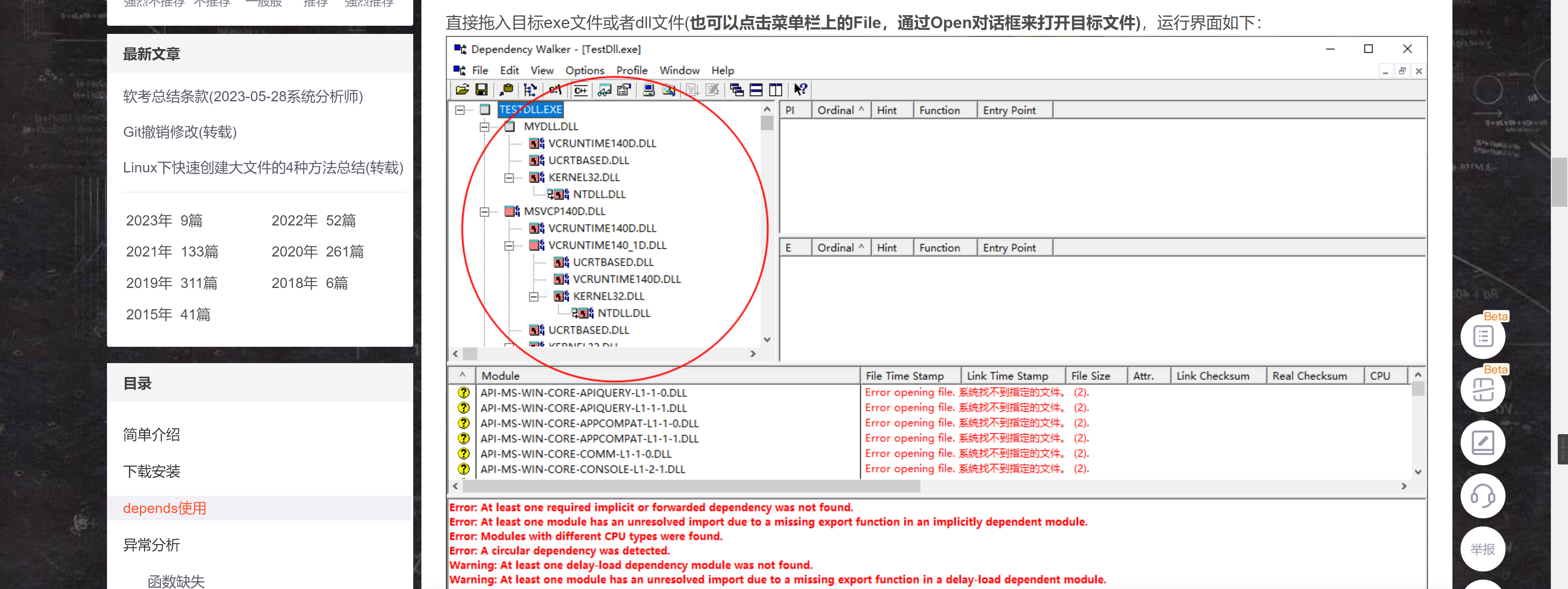
但是!

就离谱!exe文件也一样
仔细想了想,可能nltk这个库确实是没问题的,那么可能是他下面依赖的库不全的问题,继续查看报错的信息,看到最后一行

他最后要找的是ctypes这个库下的某个东西,结果没有找到,那可能出问题的是ctypes这个库?
安装一下
pip install ctypes |

打扰了,使用conda安装也装不了
又难道是scipy这个库,他说scipy>=1.4.1,我的版本是1.7.3难道是太高了吗
试试重装一个1.4.1版本的
pip install -U scipy==1.4.1 |

跑一下试试吧…

woc?!这个错解决了吗?!ohhhhhhh
弯路2
这个错感觉好说,配一下路径就行(理论上
好像是没有下载word2vec这个数据集,网上搜了一下,找到了好人发的度盘资源,下载下来康康

emmm怎么用呢,好像和程序里的目录不太一样
在论文里康康

我不会还要自己先用这个工具包先弄出点数据吧…
往下看md文档,好像下面就是训练数据了,先试试可以跳过预训练不
Train Tailored Models
python main.py \ |
把这部分改成bash语言(转换用的chatGPT)
@echo off |
然后新建一个.bat文件,把这段代码放进去跑一下试试

走起

盲猜是因为在脚本里没有选择环境(之前的经验),在脚本最前面加入这段代码
%切换到snn环境% |
跑一下

好像是又少什么包了

对比了一下,画红线的那两个包在代码里也没有啊,要不注释了试试吧

再跑试试

看了一下,下面的代码还用到了,那就退回上一步,用IDE的建议试试

可恶,还报错
观察了一下刚刚转换完的脚本,他用的是textcnn这个模型,和报错的那两个没有关系
那就!把报错的全注释8!再运行一下

好像是路径的问题,怎么会有lvchangze这个文件夹
全局搜索一下
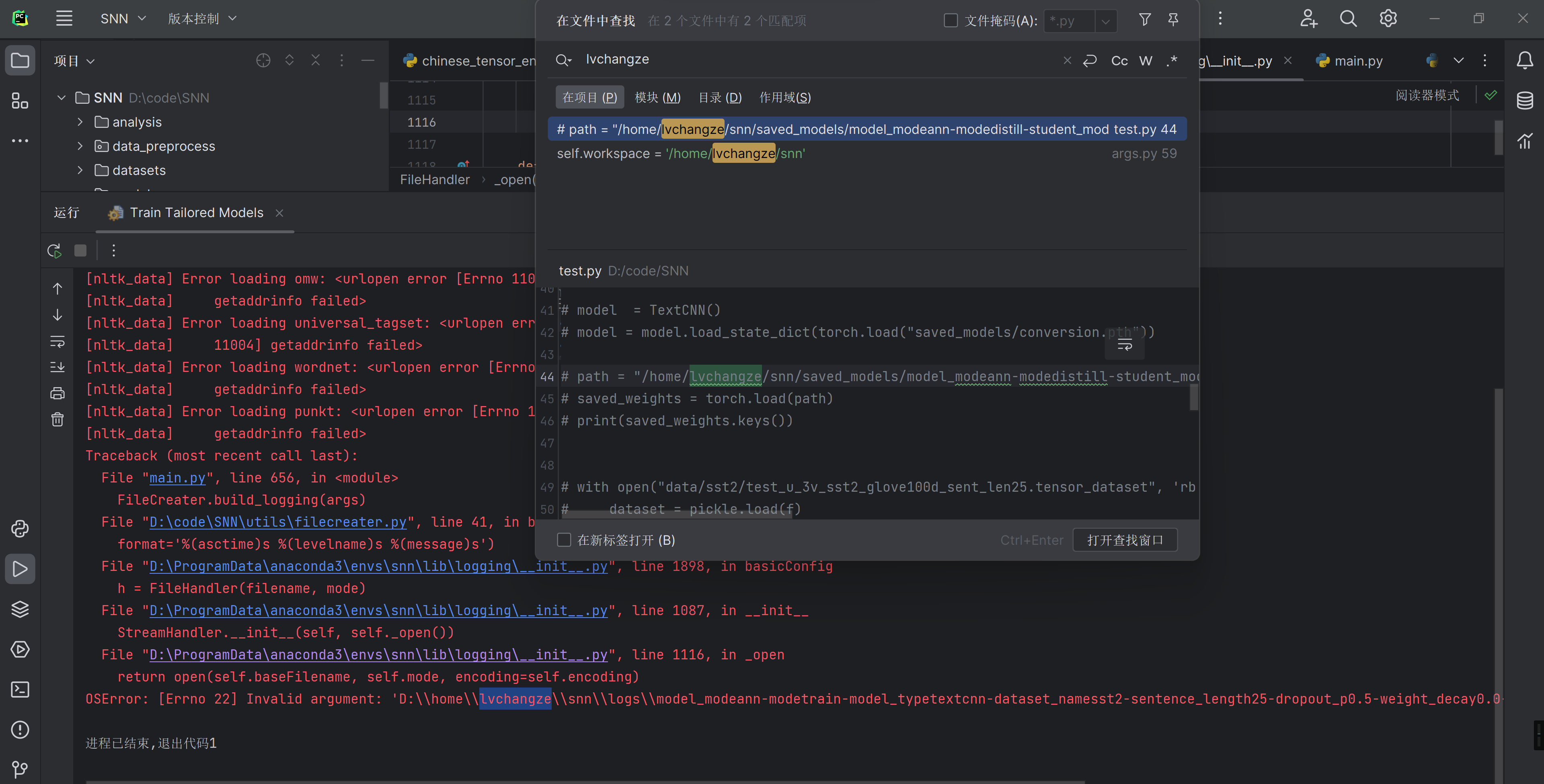
修改一下吧

再试试吧
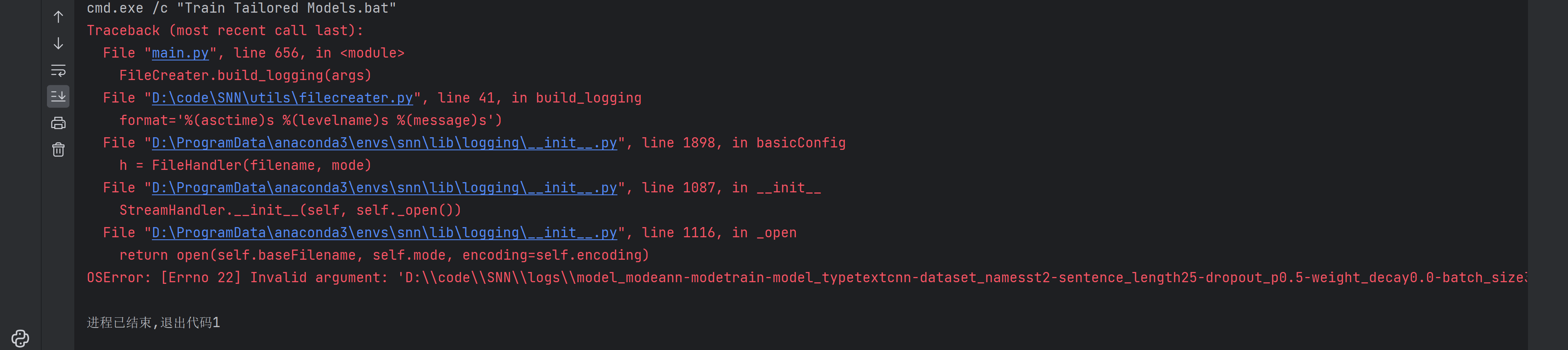
好消息是少了前面一坨红字了,网上查了一下这个错
看来可能还是路径的问题?修改一下刚刚改的路径试试
self.workspace = 'D:\\code\\SNN' |

跑一下试试

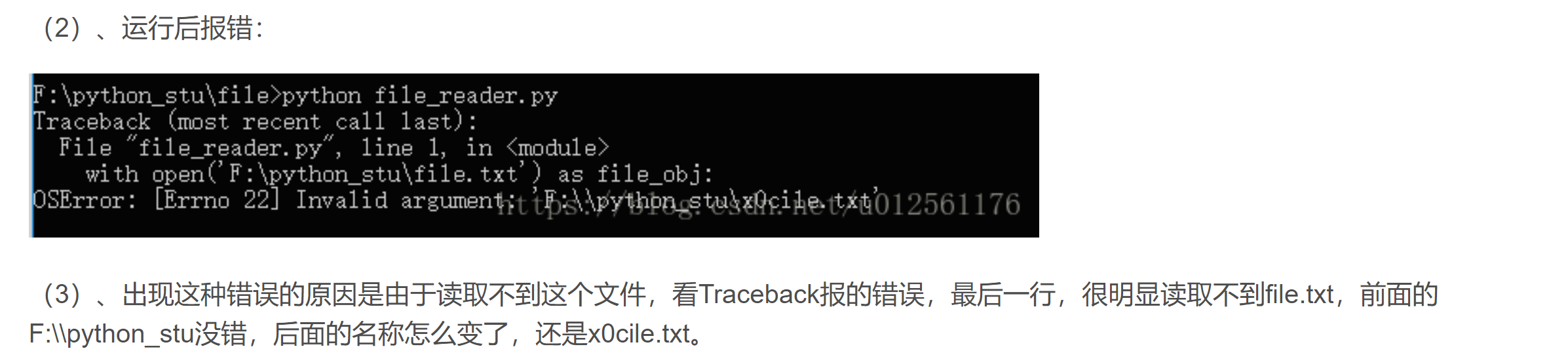
行吧,还是那个错,但是我发现这个目录最后有一个.log文件,但是实习在那个目录里却没有

难道是因为创建不了这个文件的原因,所以导致读取不到吗(可能是不是权限的问题
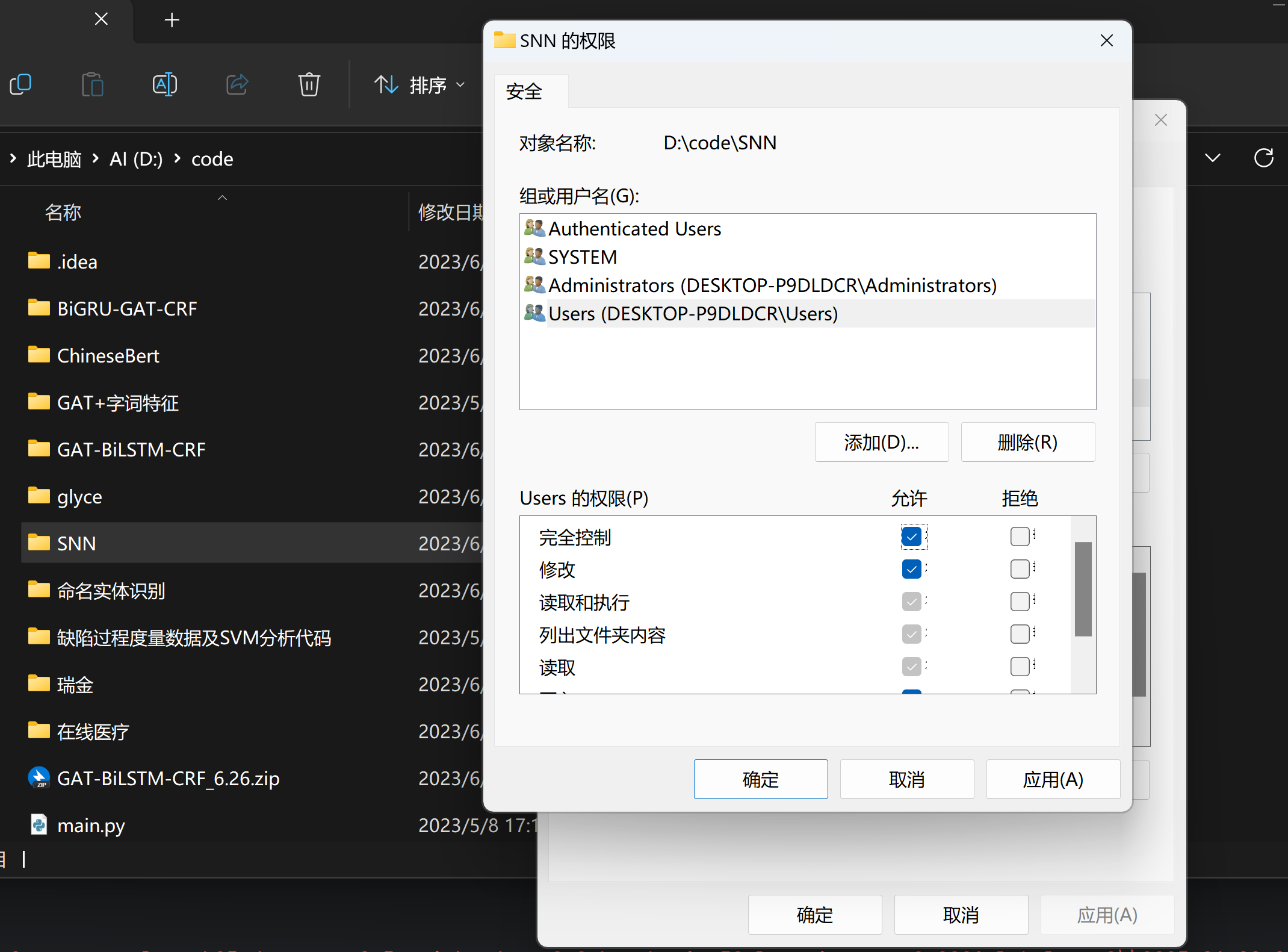
加点权限试试,然后再跑一下试试
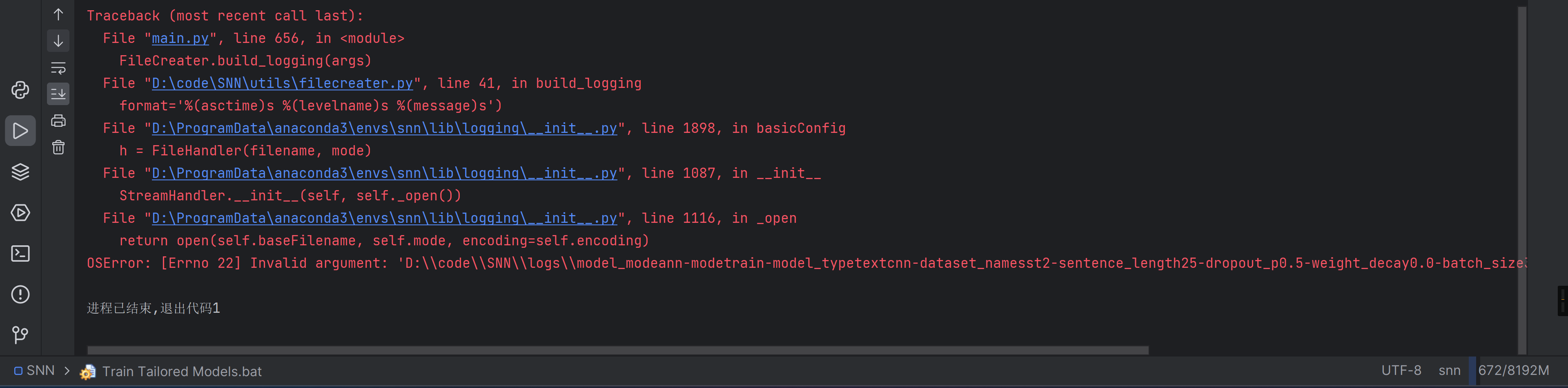
好吧,还是这个错。那试试用管理员开始bat文件?
可恶一闪而过了,加入点东西让他运行完停止
%使用read命令达到类似bat中的pause命令效果% |
再运行试试,可恶也是一闪而过
这样吧,反正这玩意是日志,应该注释了不影响

给他注释了
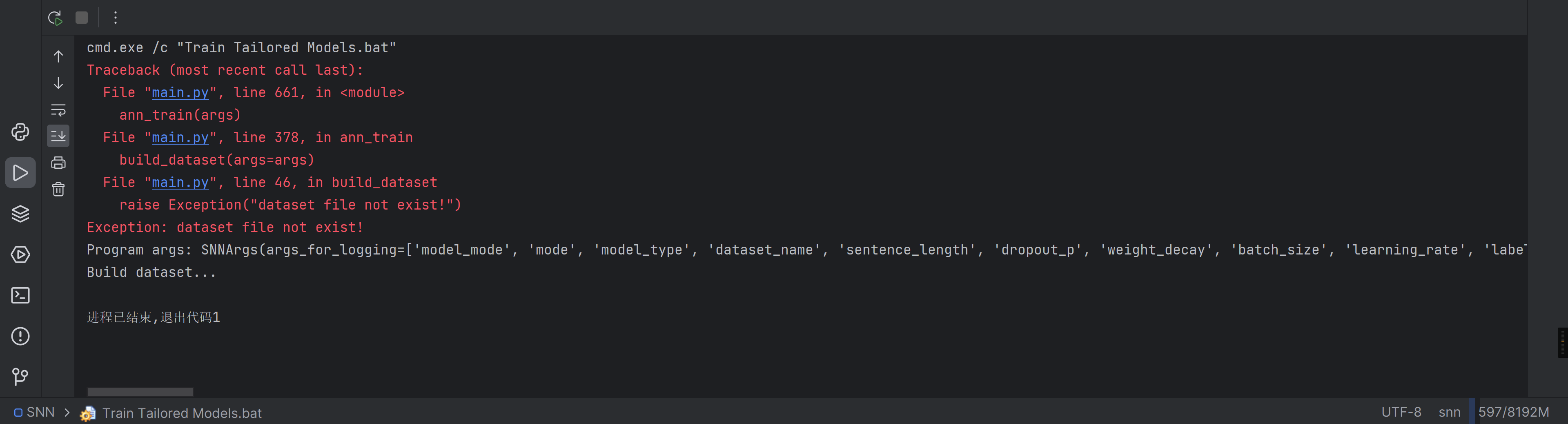
这是数据集找不见了,全局搜索一下data_path的字段
根据脚本的字段设置,找到关于ann和textcnn相关的,修改一下路径
--model_mode ann ^ |
等等有一个更好的方法,可以让程序输出一下原本data_path里的字段,然后顺着这个字段改一下就行
print("这里应该有数据集"+args.data_path) |
把上面这句加在这里

跑一下康康路径在哪
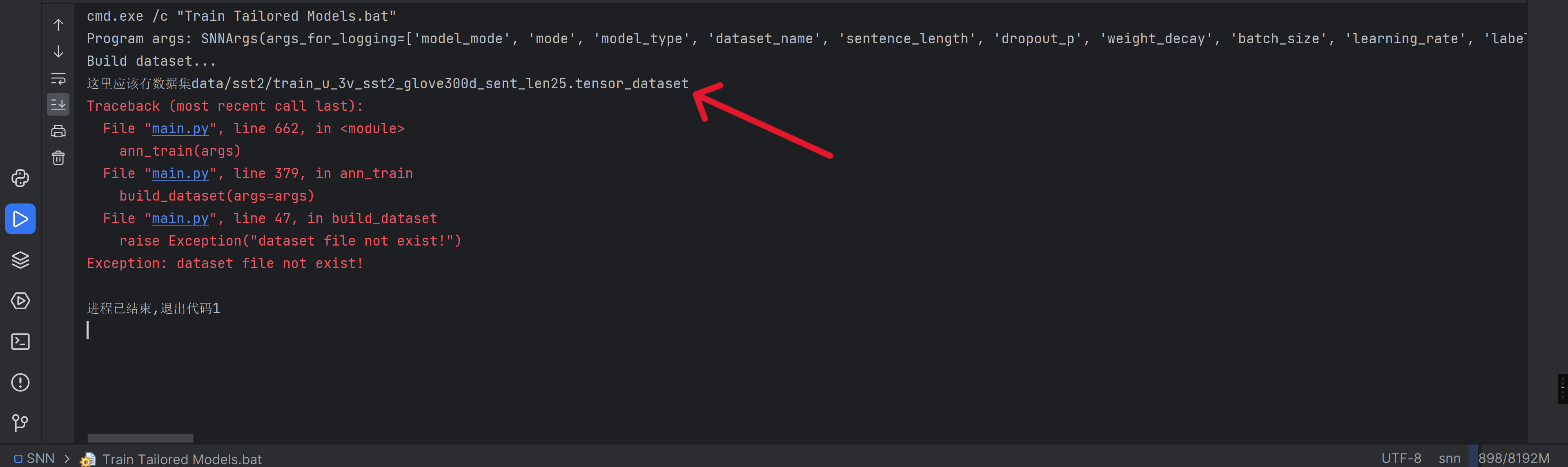
bingo!把我刚找的数据集放在这个目录下试试吧,等等我找的应该不太行
他之前的文件夹是sst2,在论文里找一下这个数据集的下载方式吧
网上搜了一下SST-2是一个什么东西
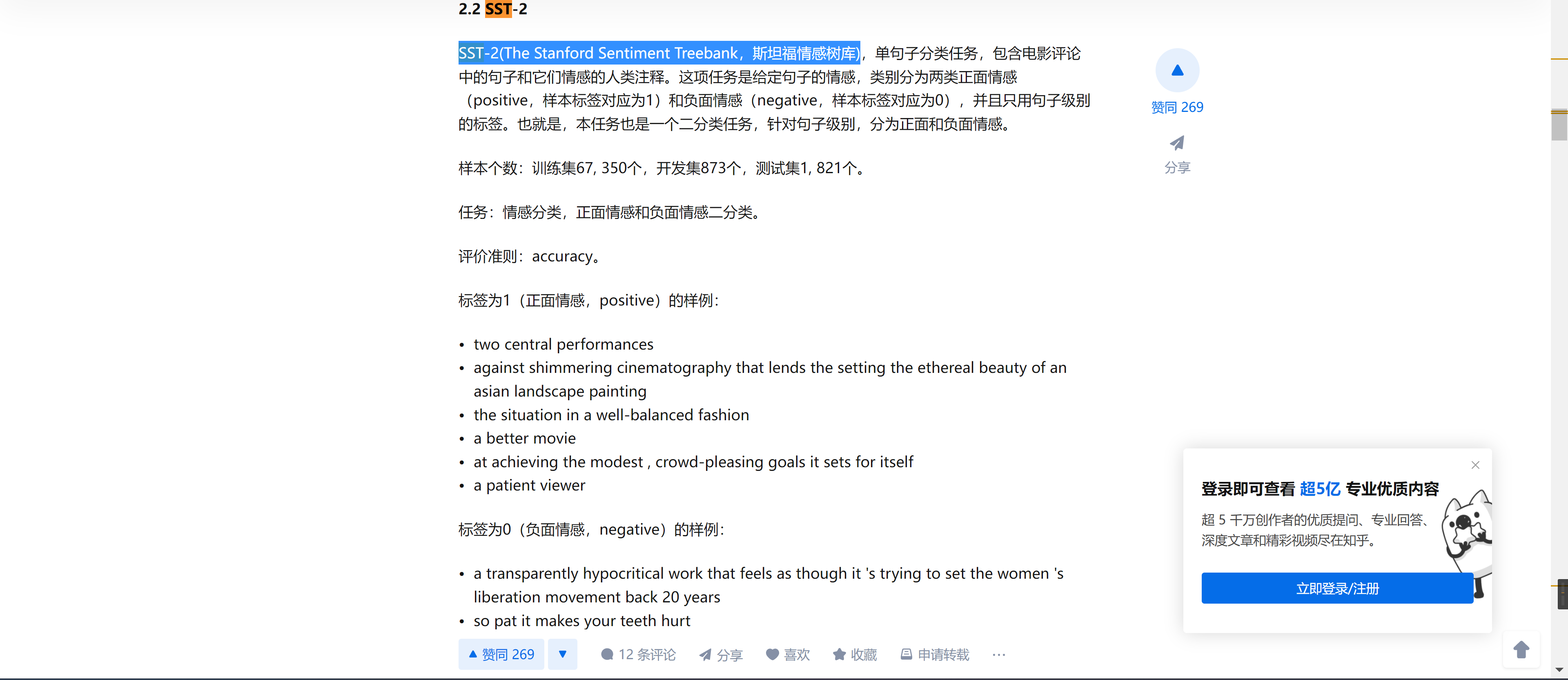
这是他论文中提供的一个数据集的下载地址,搜了一圈,发现他是把积极和消极的评论数据集分开放了
发现我又从网上找到了一个SST-2的下载地址,下载下来后解压是这些文件

试试能不能套上去吧

跑一下试试

啊好吧,可能是路径没改完,这样吧,直接在main文件里把传过来的地址改一下,把之前改的注销了

再跑一下试试

阿哲,还可以下溢的吗
弯路3
隔了好多天,网上看博客用word2vec工具把预训练集弄出来了,这次试试吧
这次跑完生成了如下几个文件

试试把预训练的代码改一下
跑一下data_preprocess/chinese_tensor_encoder.py试试吧

有毒,那把第一个文件改成wiki.zh.text.model.syn1neg试试
vocab_path="../word2vec/wiki.zh.text.model.syn1neg" |

看来没有这个文件还是不太行啊
将预训练的词嵌入转移到 [0, 1]
又过了一段时间,联系到了原作者,热心的作者给我发了这个文件!!!!
链接:https://pan.baidu.com/s/1eHcj8bvbQPAg76v7D_Xs8A |

跑一跑试试吧

解决编码问题
好像是编码的问题?
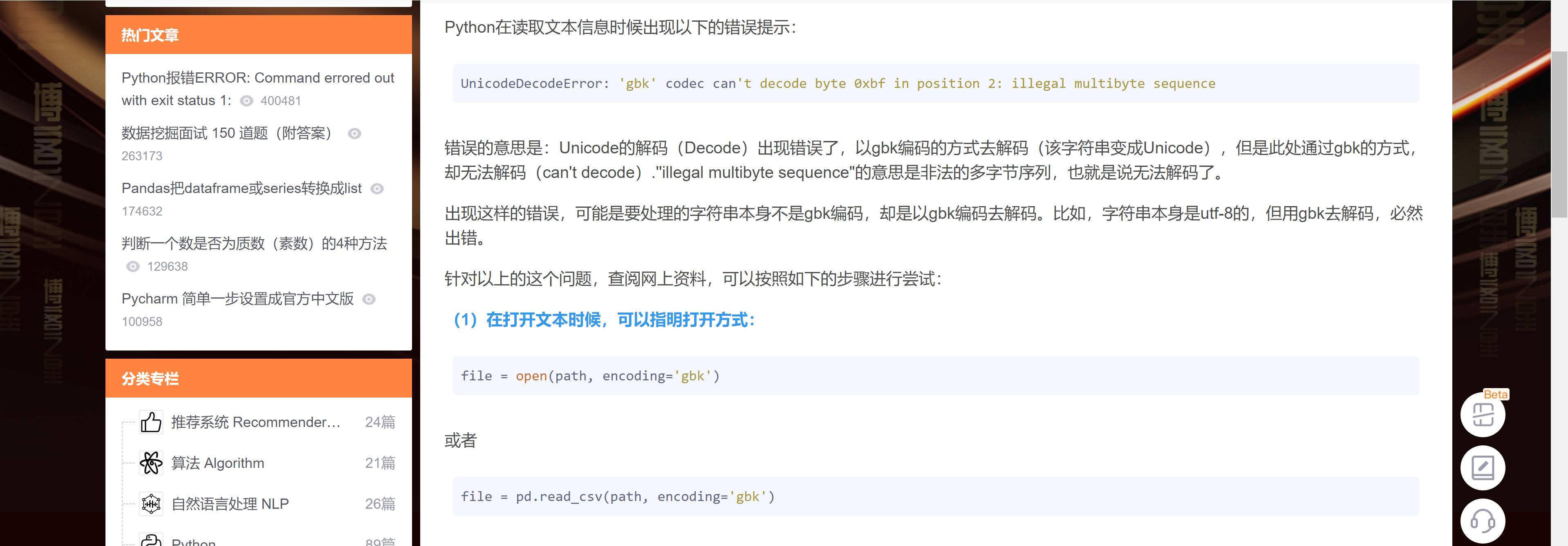
把里面的代码改改试试
with open(self.vocab_path, "r") //旧 |
再跑试试?

这是在跑吗好像,先等会康康吧
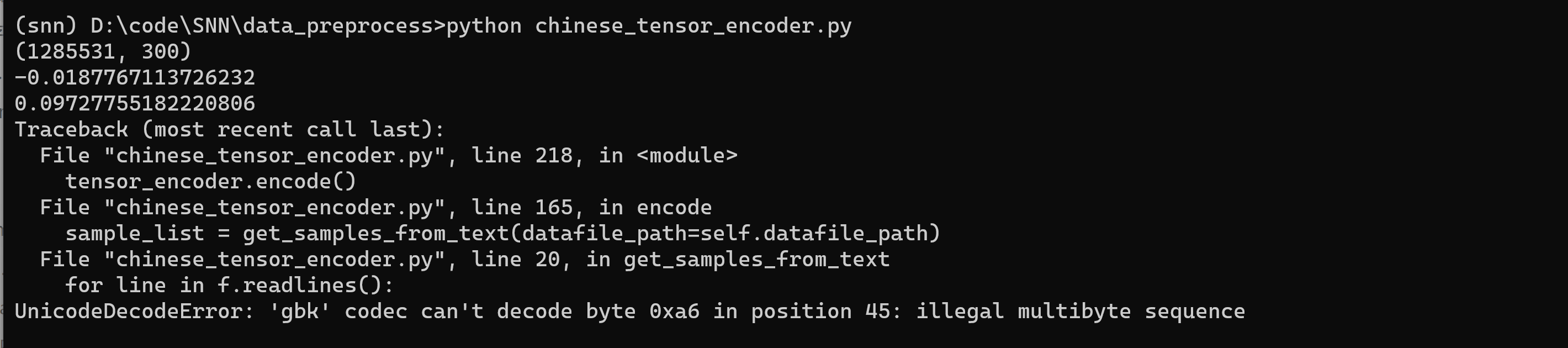
看来可以跑,应该是刚刚没改干净,看来和open有关的都需要改
with open(datafile_path, "r") as f: //旧 |
再跑试试
python chinese_tensor_encoder.py |
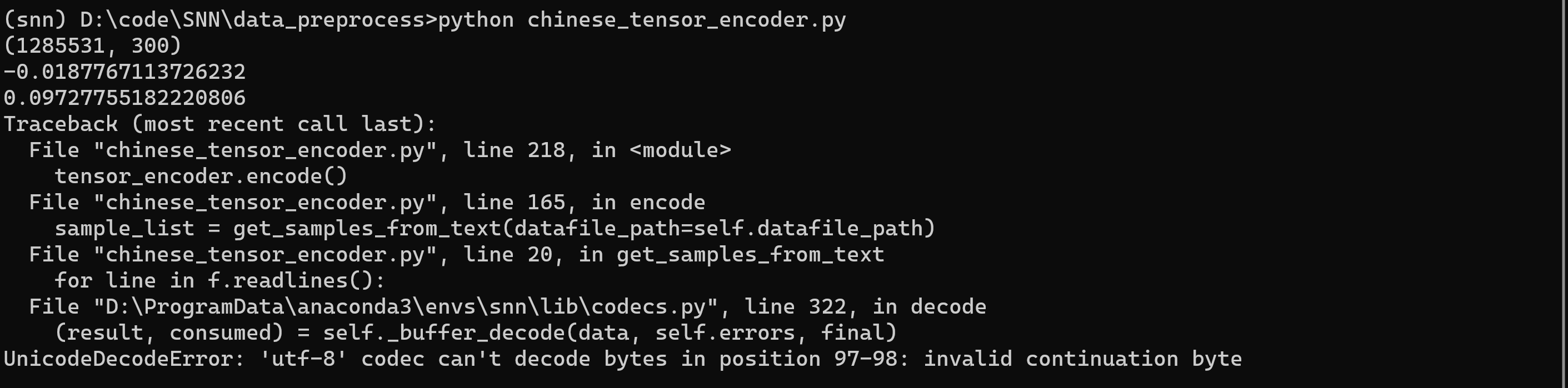
还有错?!继续查查怎么改

试试直接ignore了,不对,可能是我的数据集的问题
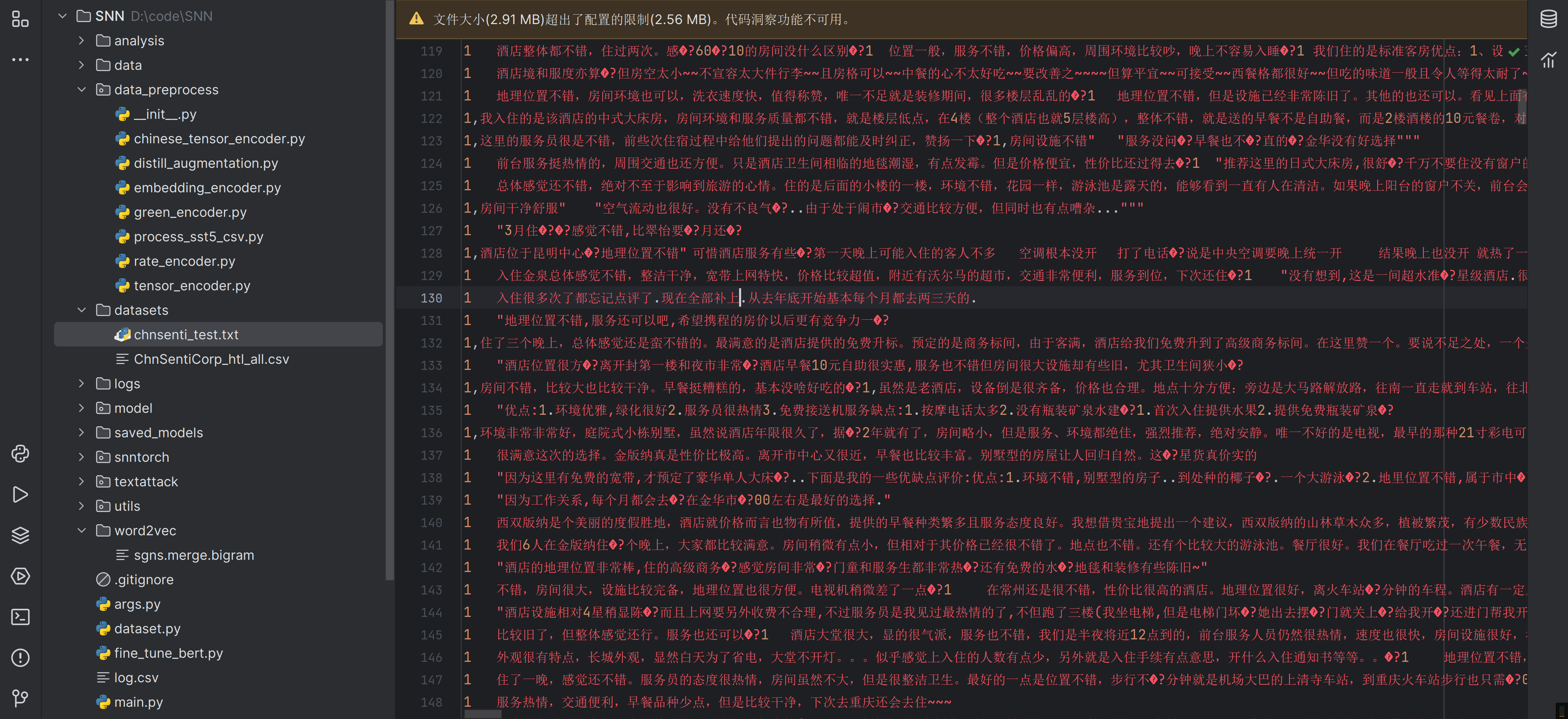
把ChnSentiCorp_htl_all.csv的内容直接复制到chnsenti_test.txt中,用utf-8就不会出现乱码了
再跑跑试试
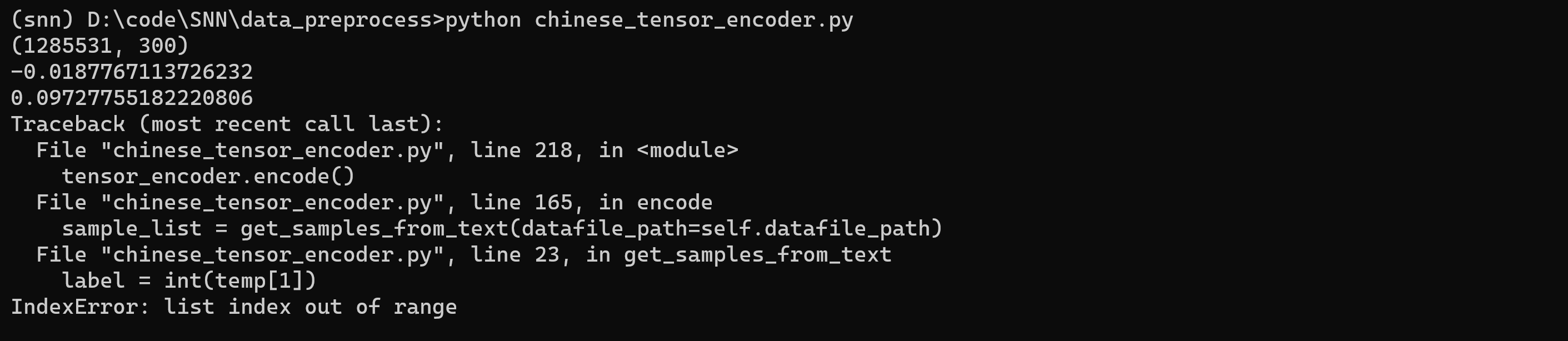
6!把数据集直接改成ChnSentiCorp_htl_all.csv这个文件试试
emmm还是这个错,有仔细观察了一下,好像是label在第一个,句子在第二个,那感觉和代码里的就反过来了
之前的代码:
sentence = temp[0].strip() |
改后:
sentence = temp[1].strip() |
再跑试试吧
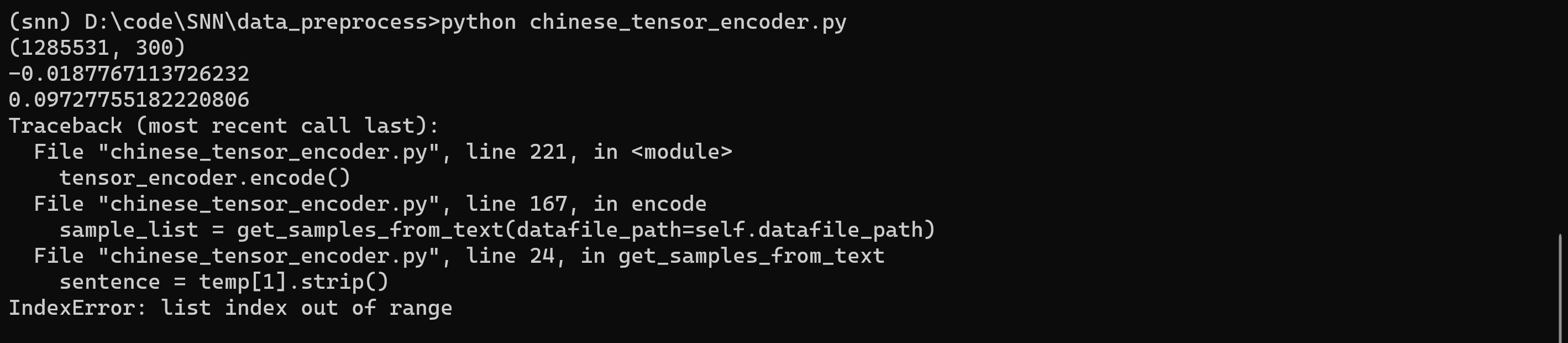
emmm用Pycharm还不能直接运行,只能在命令行里运行
等等我知道我为什么pycharm运行不了了
之前迁移过一次环境从C盘到D盘,试了试这个博客的方法,把这个问题解决了
调试了一下,发现要把数据集最开始的一行删了,感觉是那个导致的报错
再跑试试,发现还是那个错
我感觉可能是数据集变了处理数据的内容需要修改一下
康康chatGPT是怎么处理的吧:
可以使用Python中的字符串操作来提取这个句子并将它分别存放在label和sentence字段中。
text = '1,"距离川沙公路较近,但是公交指示不对,如果是""蔡陆线""的话,会非常麻烦.建议用别的路线.房间较为简单."\n' |
输出结果为:
1 |
按照这个把代码改一改,原代码
with open(datafile_path, "r", encoding='utf8') as f: |
改完
with open(datafile_path, "r", encoding='utf8') as f: |
跑跑试试
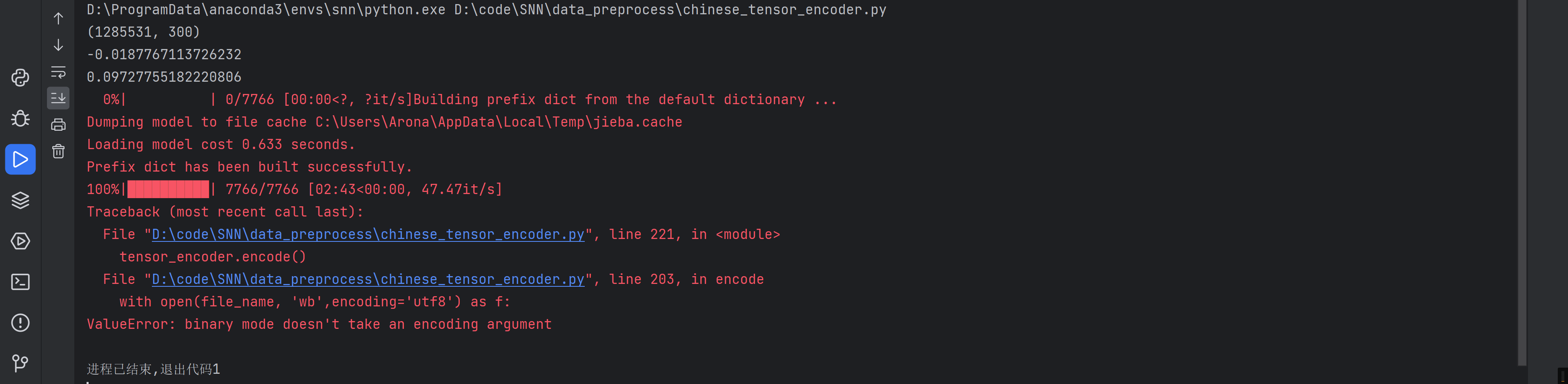
感觉有希望了耶,试试把报错那句的utf8去掉试试。再跑试试
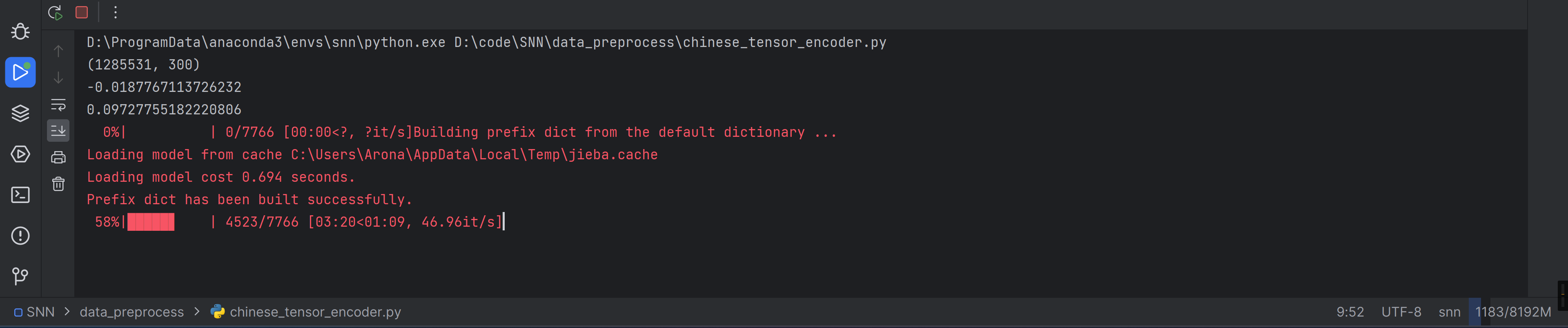
别报错别报错×114514
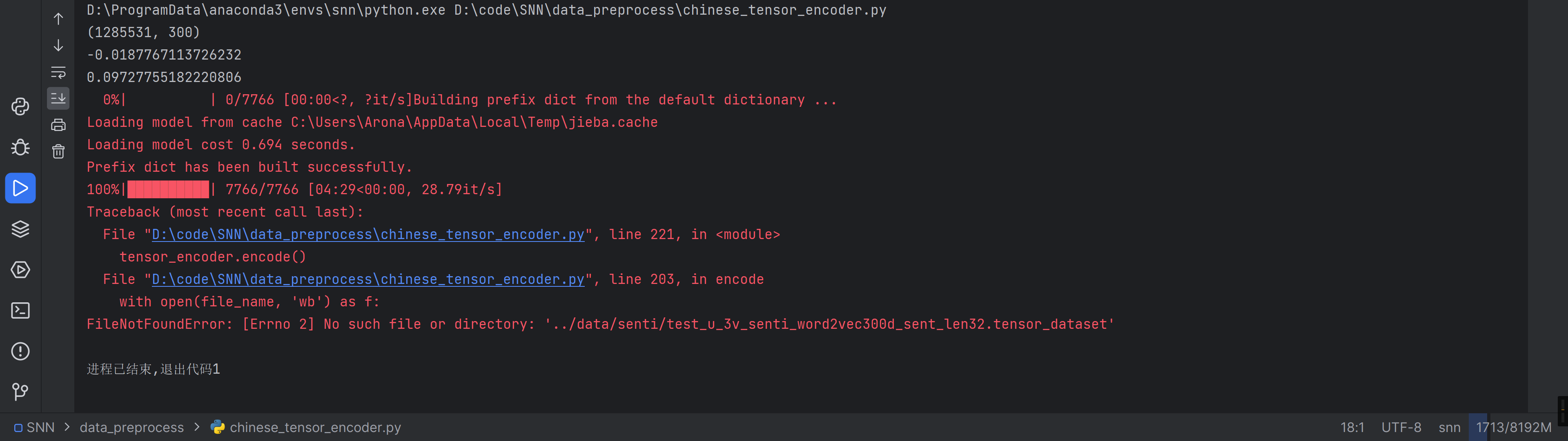
居然说我找不到文件,建个叫senti的文件夹试试
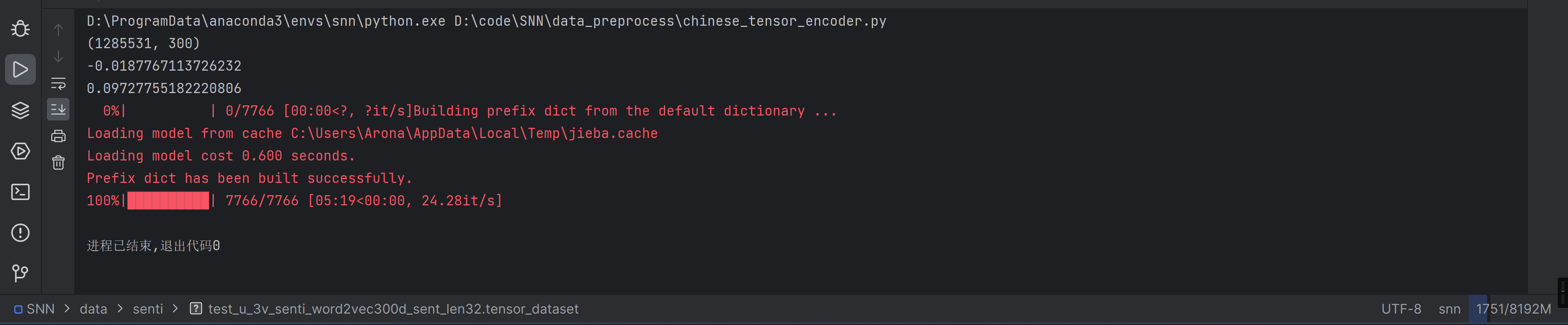
训练定制模型
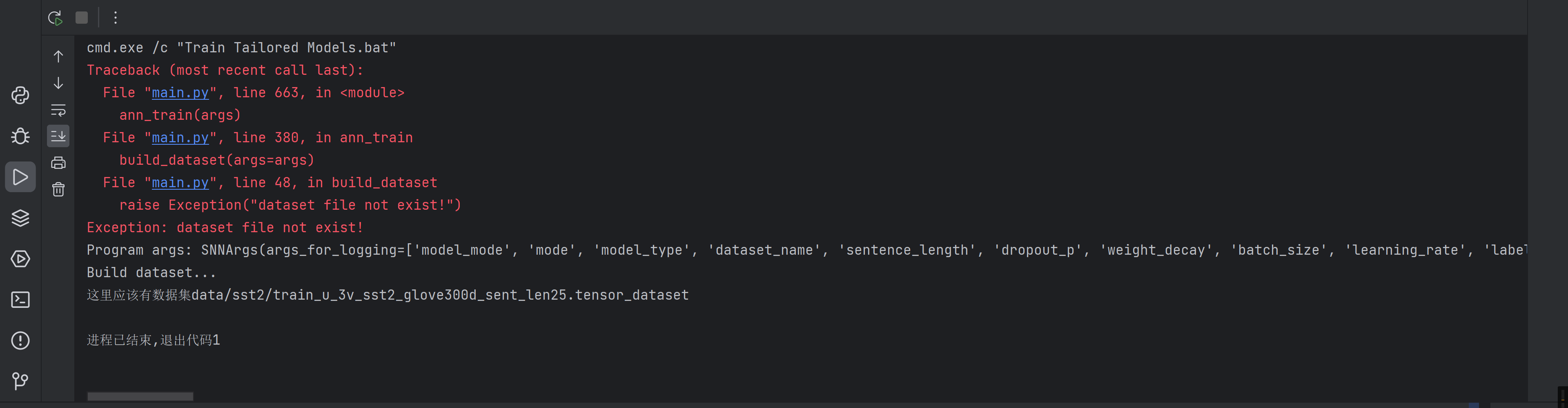
好像又是少文件,试试把刚刚跑出来的文件重命名为train_u_3v_sst2_glove300d_sent_len25.tensor_dataset试试
啊这,再把上面跑出来的文件复制一份改个名过去康康
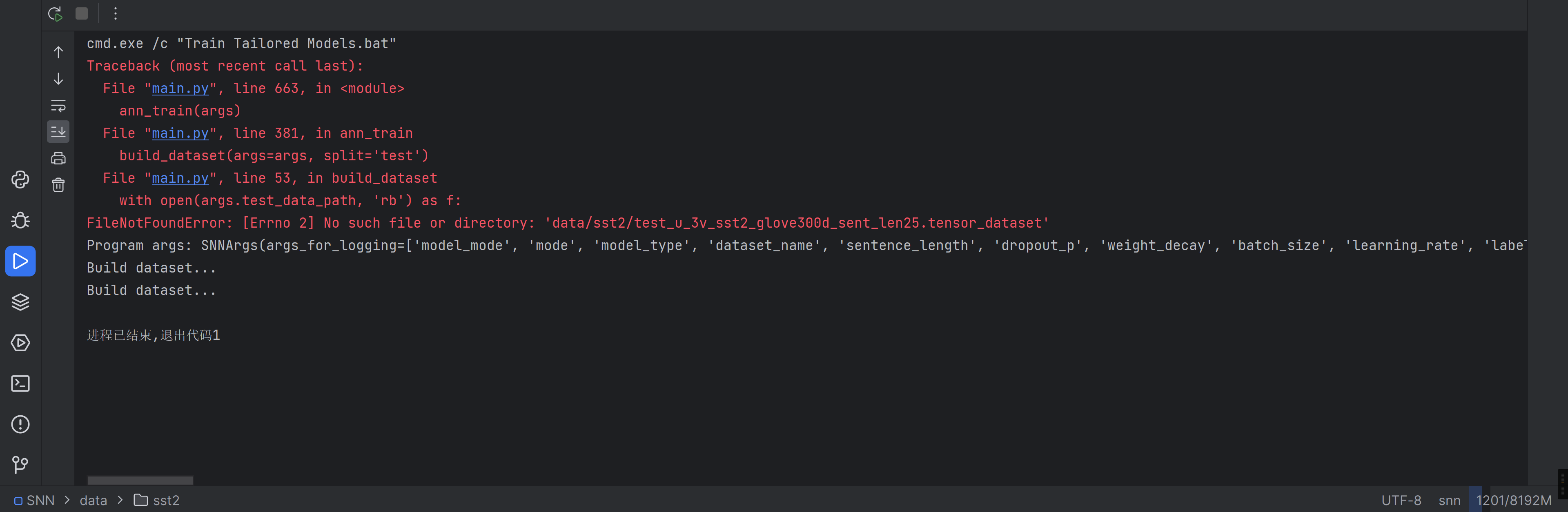
我怎么没看懂哪错了,从下往上看,找到最后项目代码报的那一行错
torch.save(model.state_dict(), save_path) |
好像是我之前把日志那行代码注释了导致的
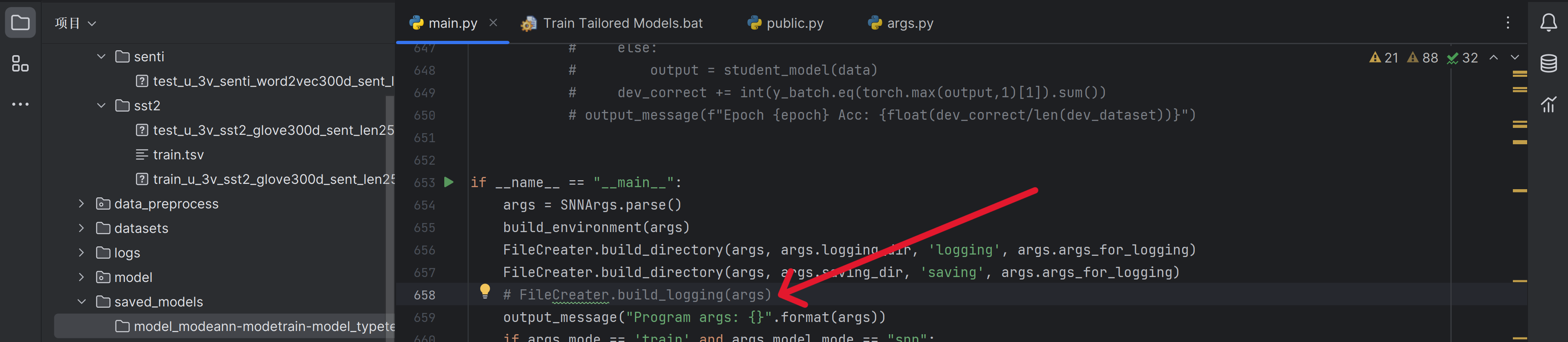
解除注释试试
又是文件读写的问题,好像日志文件就是创建不了,难道是系统权限的问题吗
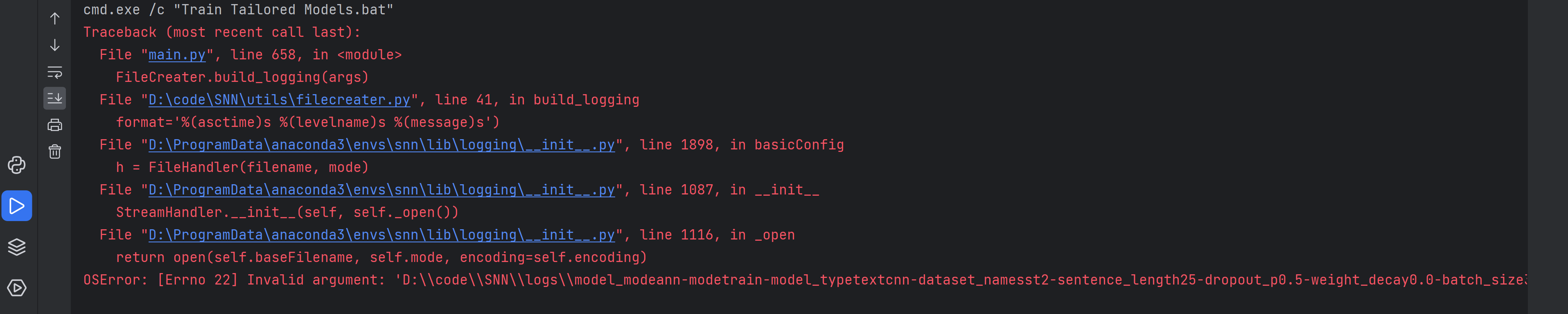
解决报错OSError:[Errno 22] Invalid argument
试试用管理员身份运行试试
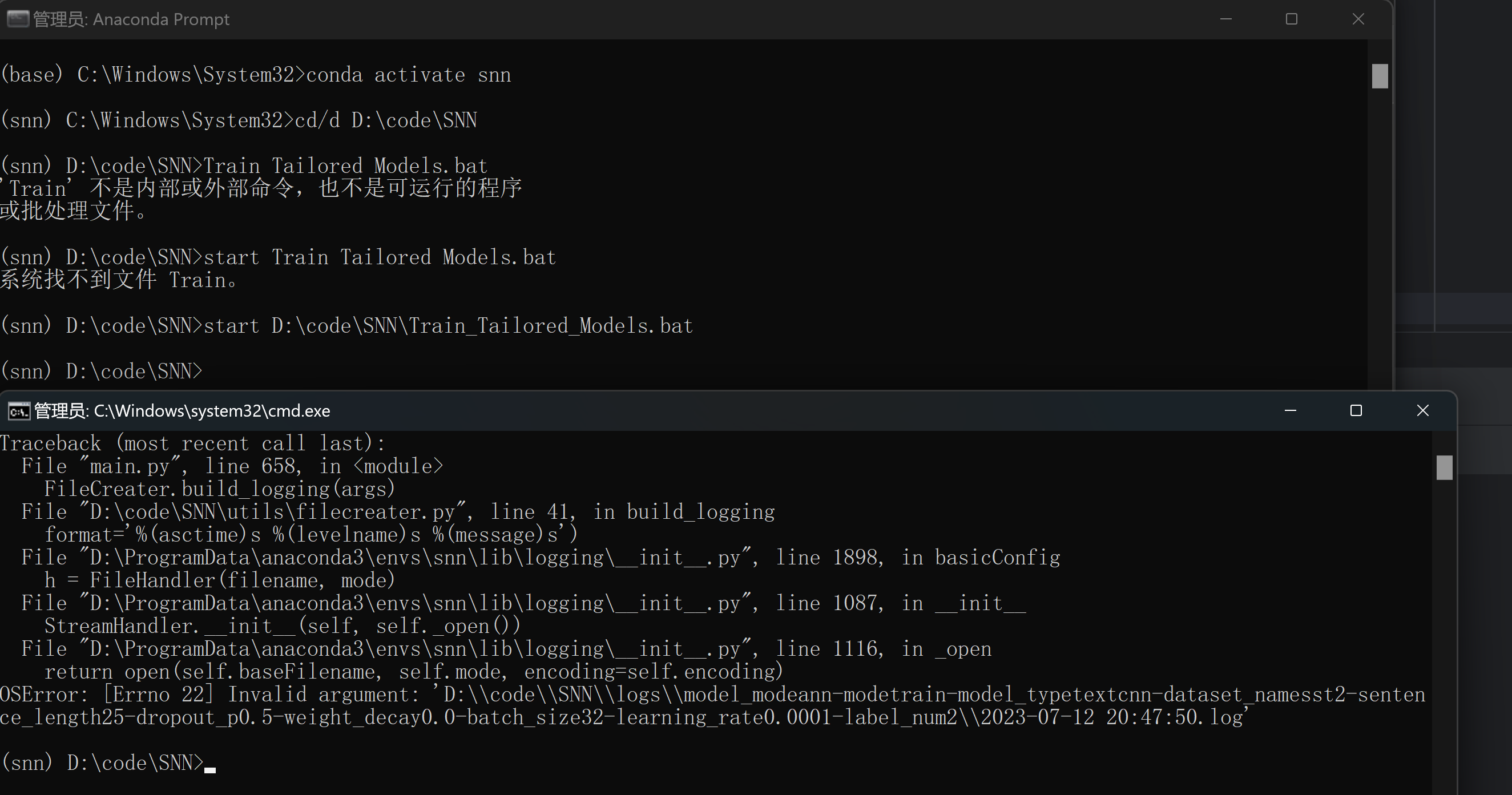
看来不是权限的问题,突然网上看到了这个,我感觉很有道理耶
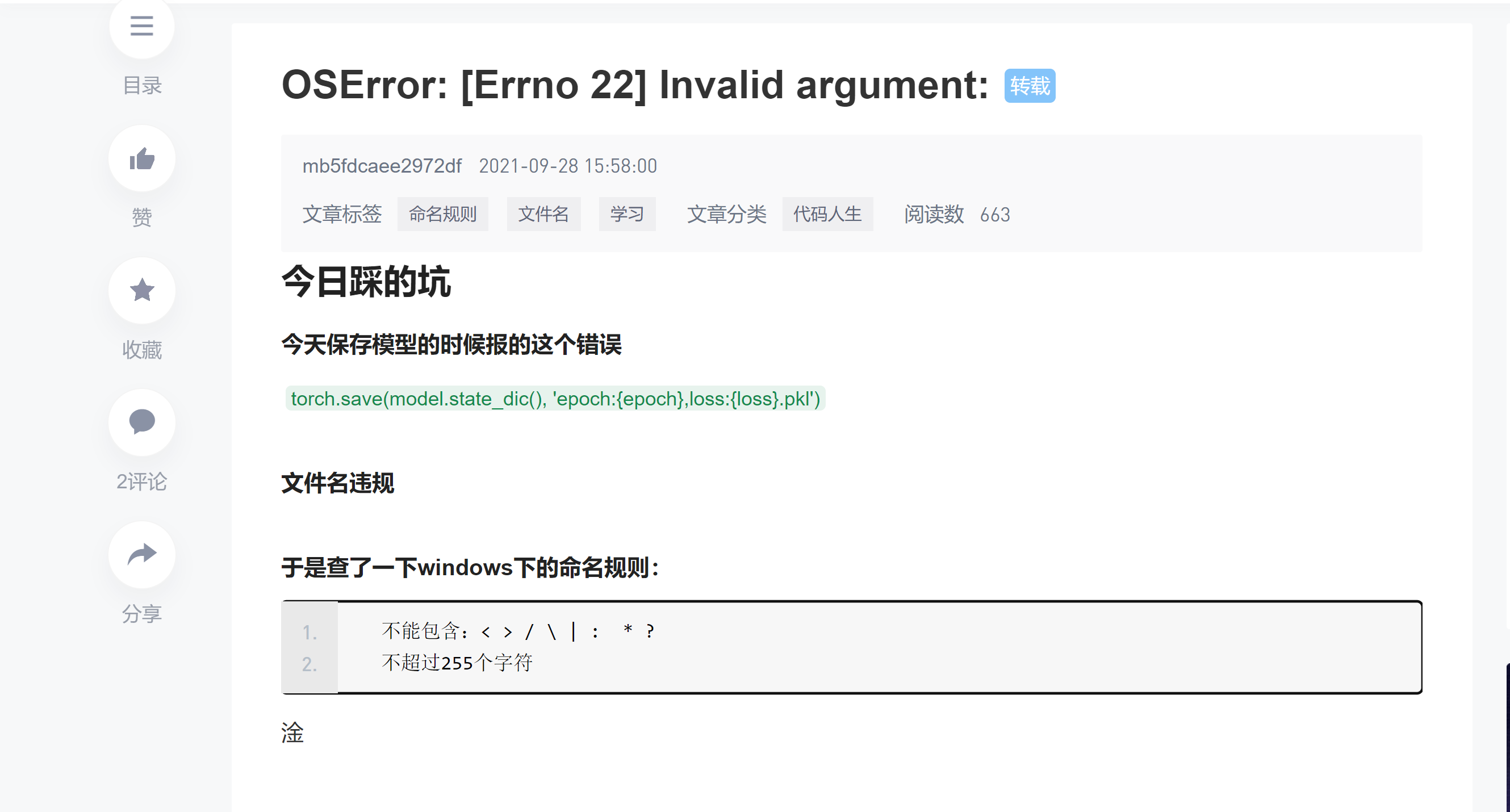
不能用冒号啊!!!!!!!!!!!!!!!!!!!!!!!
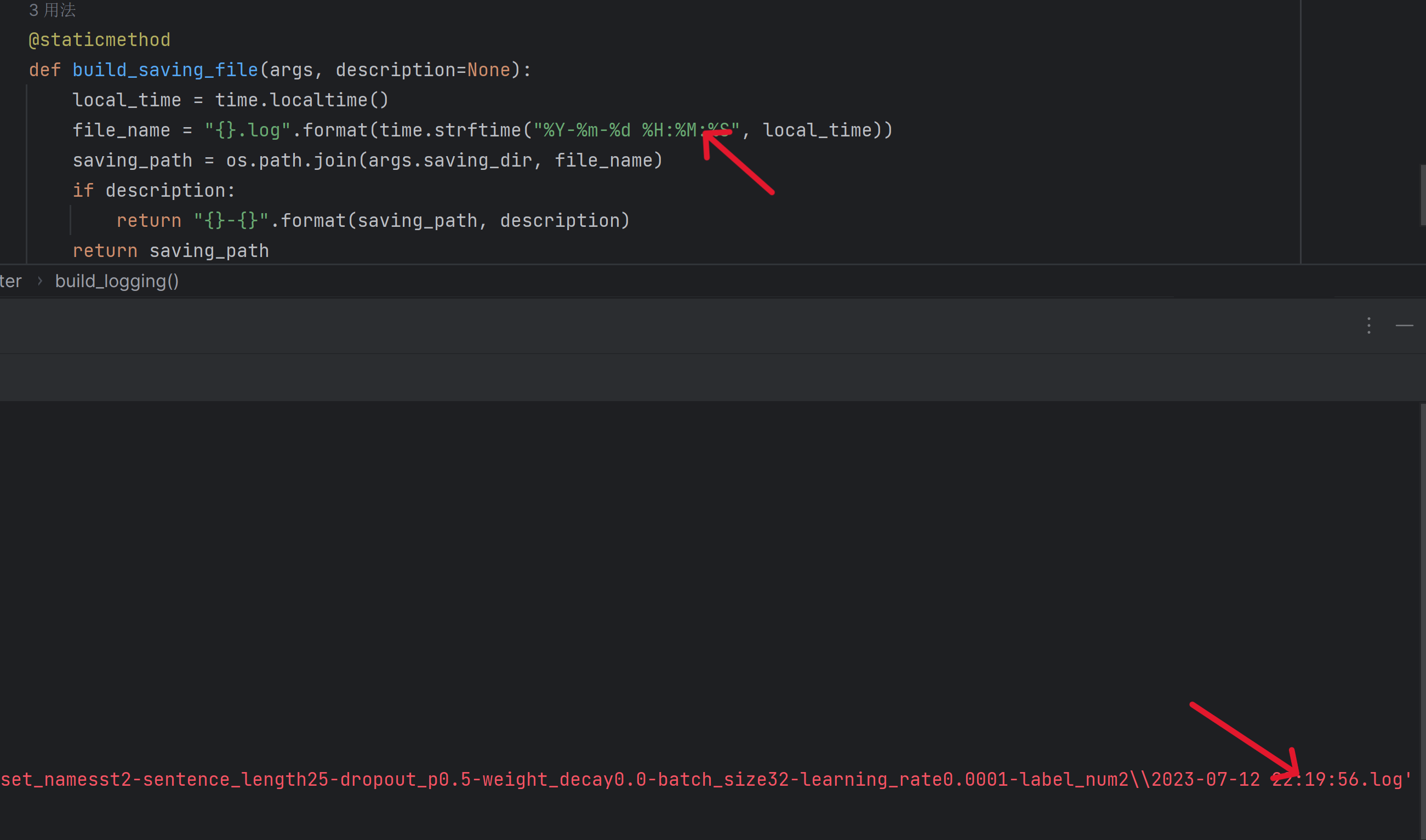
瞬间知道怎么改了
把这句改一下
file_name = "{}.log".format(time.strftime("%Y-%m-%d %H:%M:%S", local_time)) //旧 |
跑一次试试
 怎么还有冒号
怎么还有冒号

把这里全局搜索到的都改一下试试
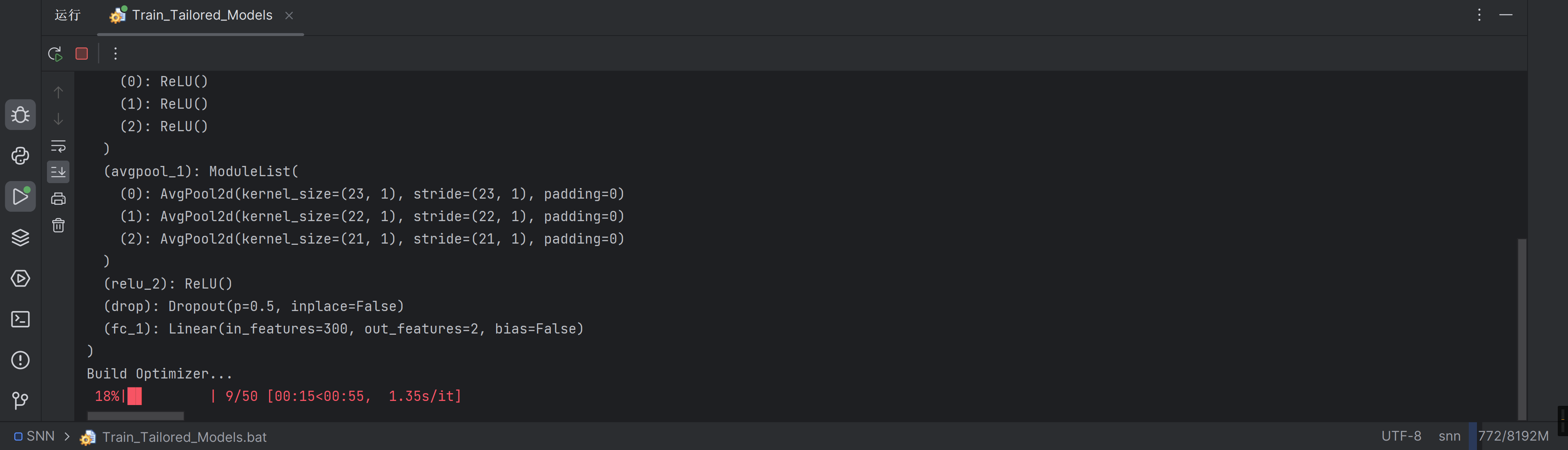
难道有戏?!
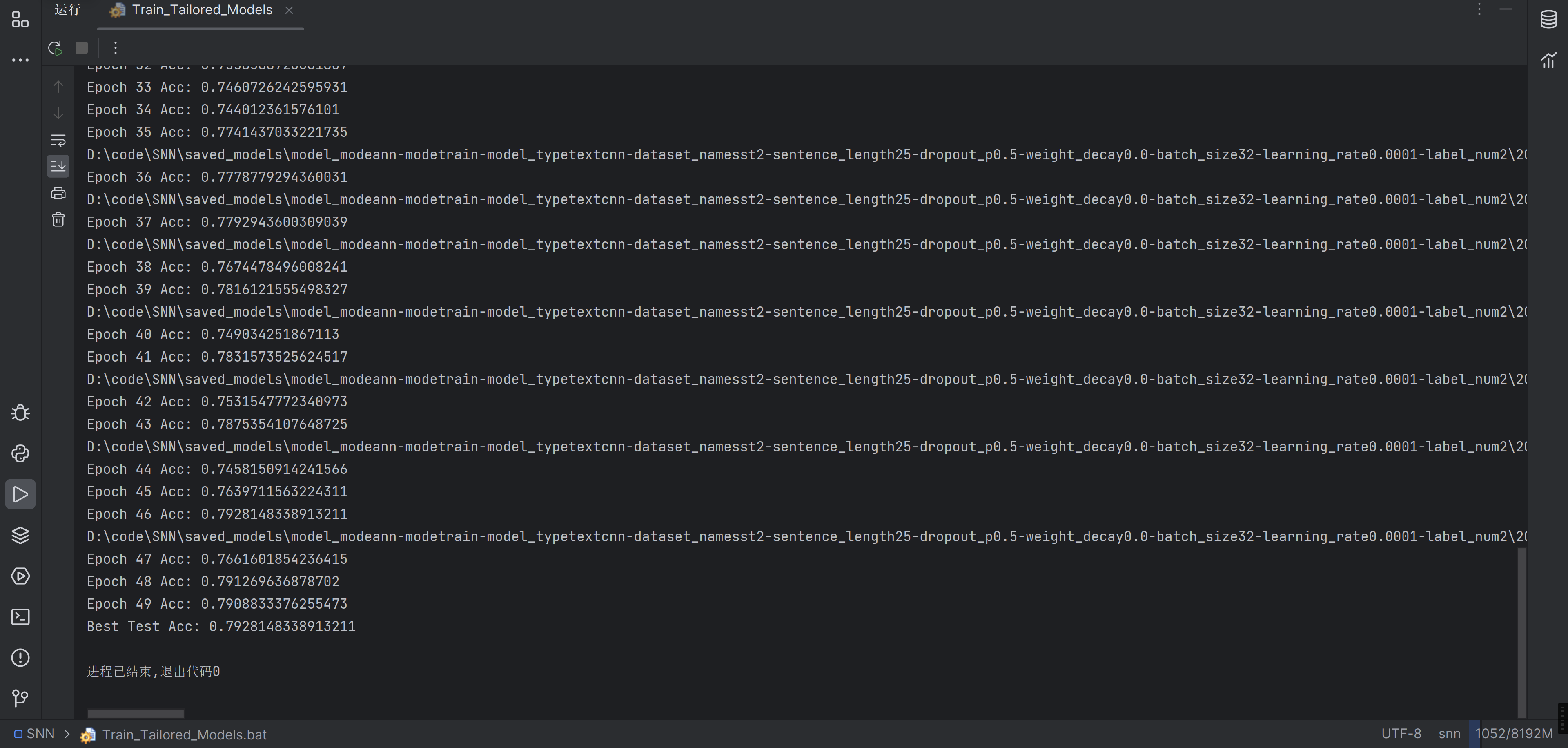
对比一下作者的结果

为什么作者的好高啊
转换+归一化
接下来就是把这句改成批处理的代码
python main.py \ |
转换完后,在前面加上切换环境的代码
@echo off |
跑一下试试
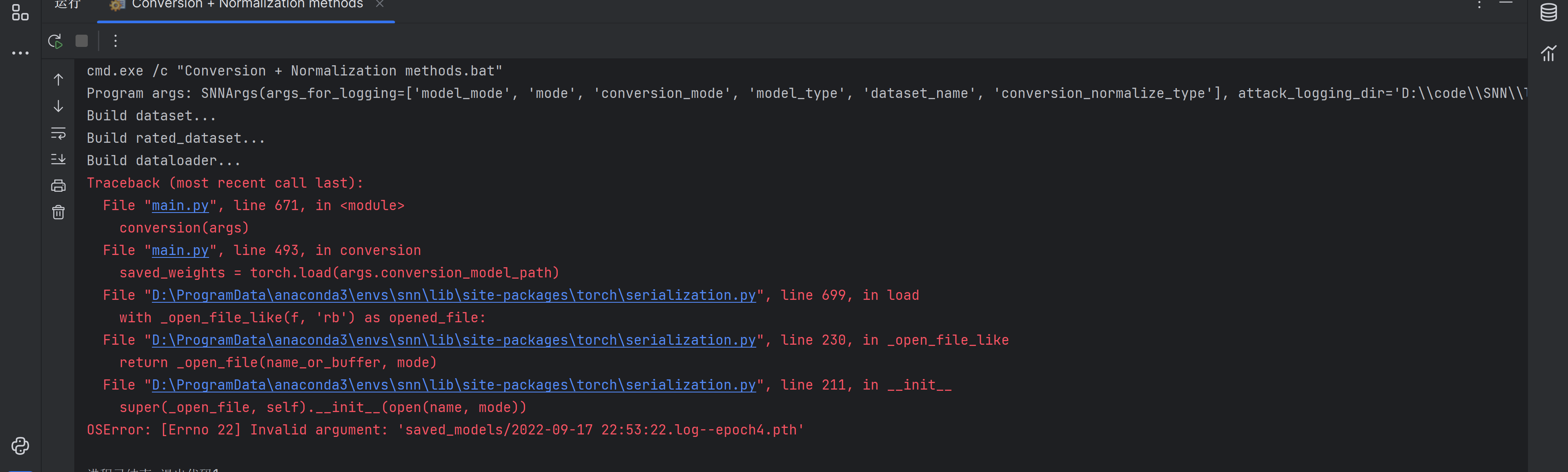
这题我会!又是文件名不符合Windows的命名规则(说人话就是不能出现):
在全局搜一下%H:%M:%S关键字,但是我搜到的全改了啊
突然一看报的时间,咦?为什么是2022年的呢,可能是不是写死文件名了
顺着搜了一下
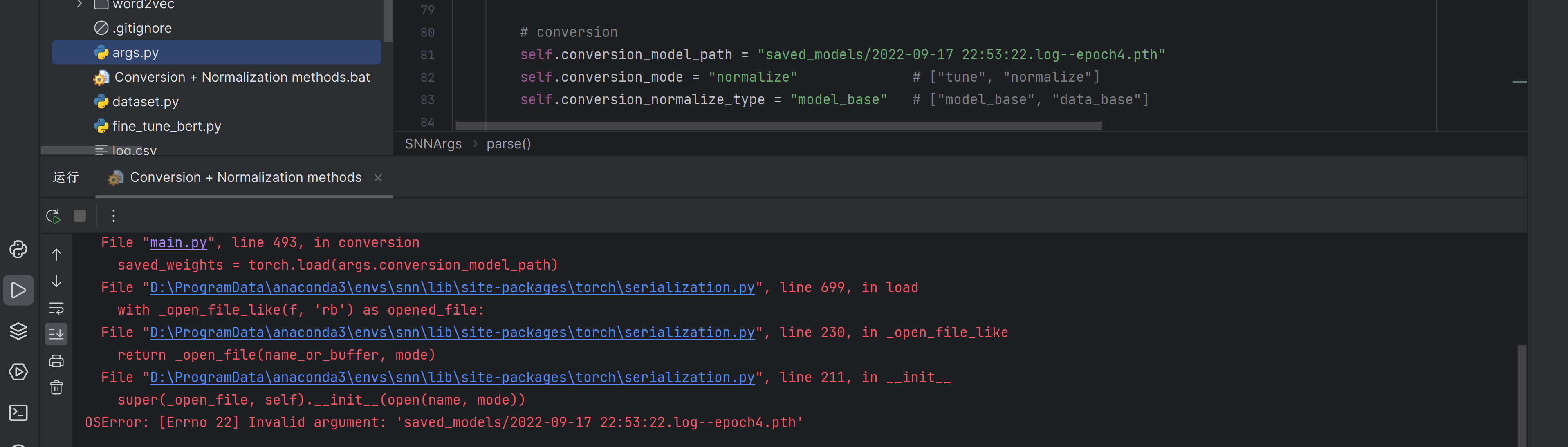
果然!!!把后面那部分去了试试
self.conversion_model_path = "saved_models/2022-09-17 22:53:22.log--epoch4.pth" //旧 |
再跑跑试试

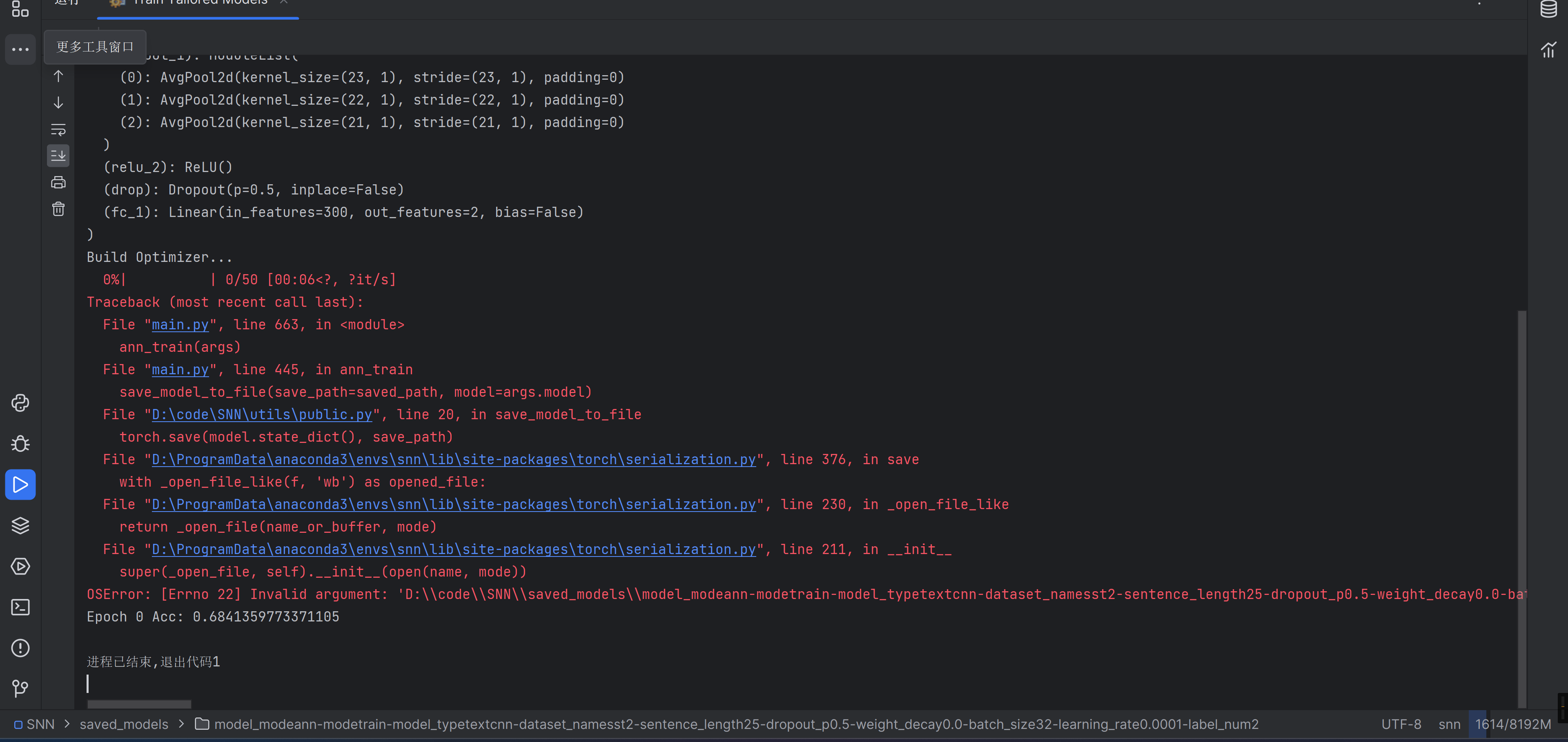
为什么拒绝访问鸭。我懂了,应该是要加载某个文件,我试试加载一个文件试试
self.conversion_model_path = "saved_models/model_modeann-modetrain-model_typetextcnn-dataset_namesst2-sentence_length25-dropout_p0.5-weight_decay0.0-batch_size32-learning_rate0.0001-label_num2/2023-07-12 22-29-13.log--epoch46.pth" |

虽然但是,为什么精度还下降了一点emm。不过我的推理没错,这里果然是要加载一个文件,跑起来就算成功
以下是作者的结果,好神秘只有Conv SNN + MN这一项和作者比较接近
转换 + 微调
还是惯例,把下面的代码换成Windows下能运行的
python main.py \ |
换成.bat文件后,加上环境
@echo off |
运行试试
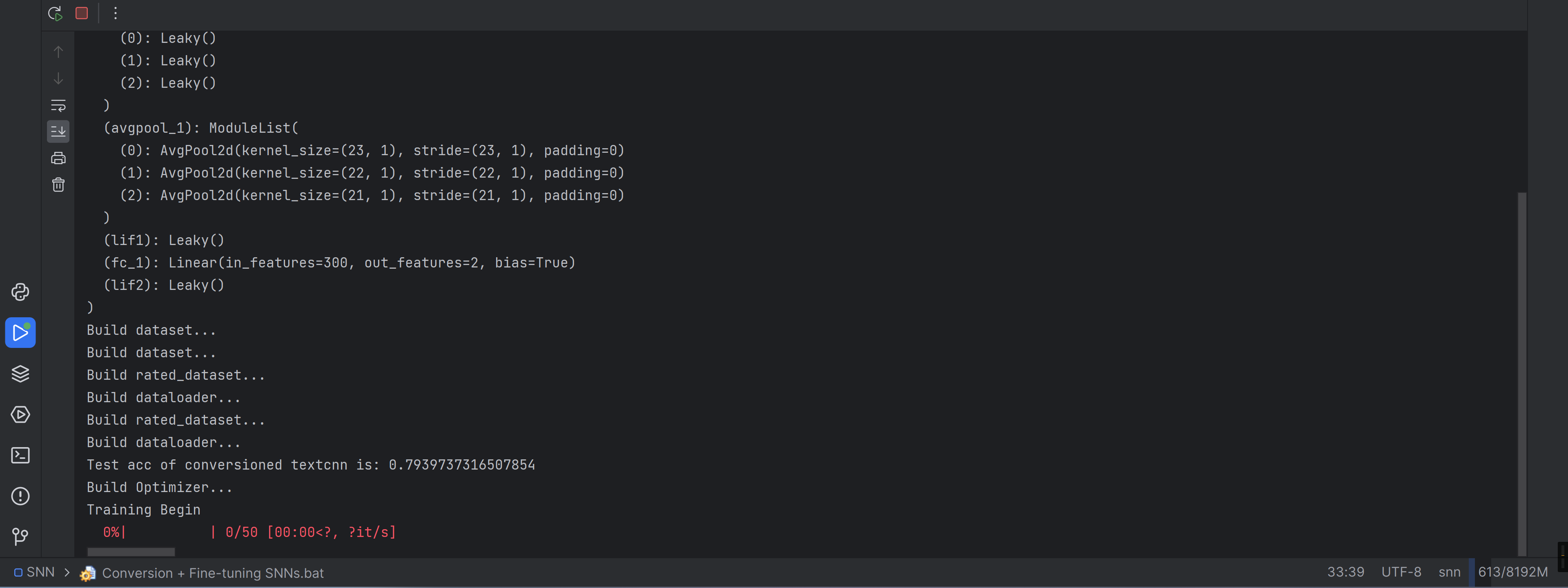
为什么不动鸭,再等等吧
速度好慢,一直挂着吧

半小时走了20%

过了一小时,又走了20%多
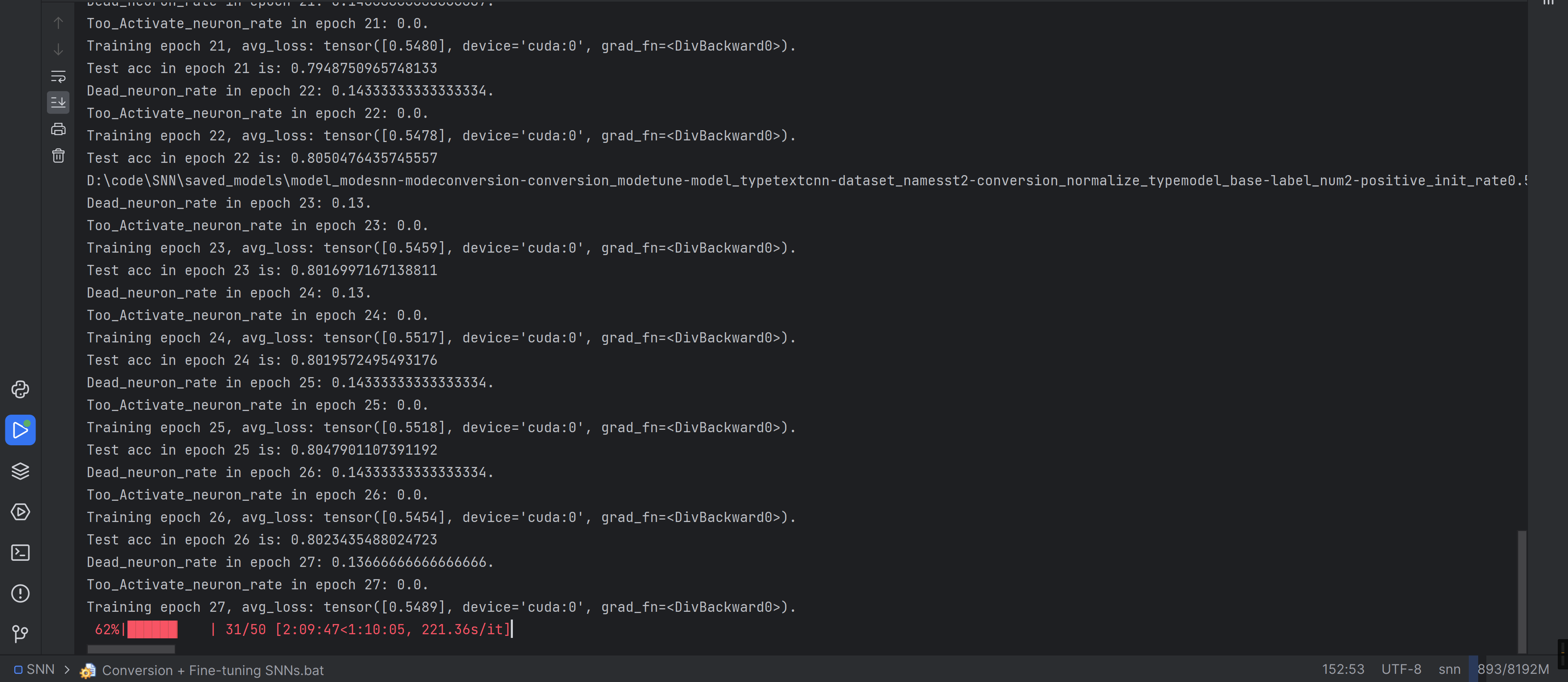
又过了一小时,说起来这玩意占资源占的好多
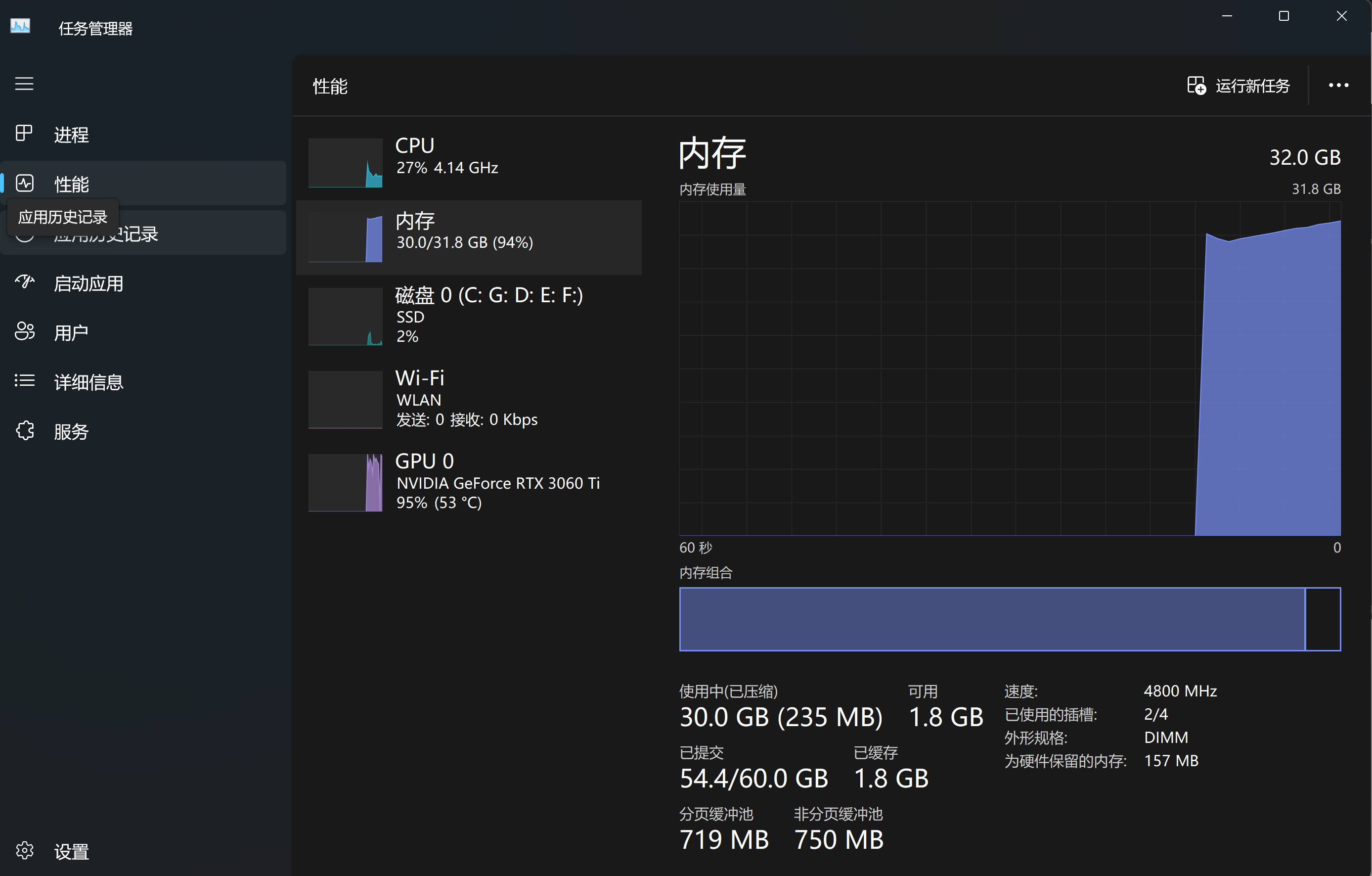
又过了一个多小时….
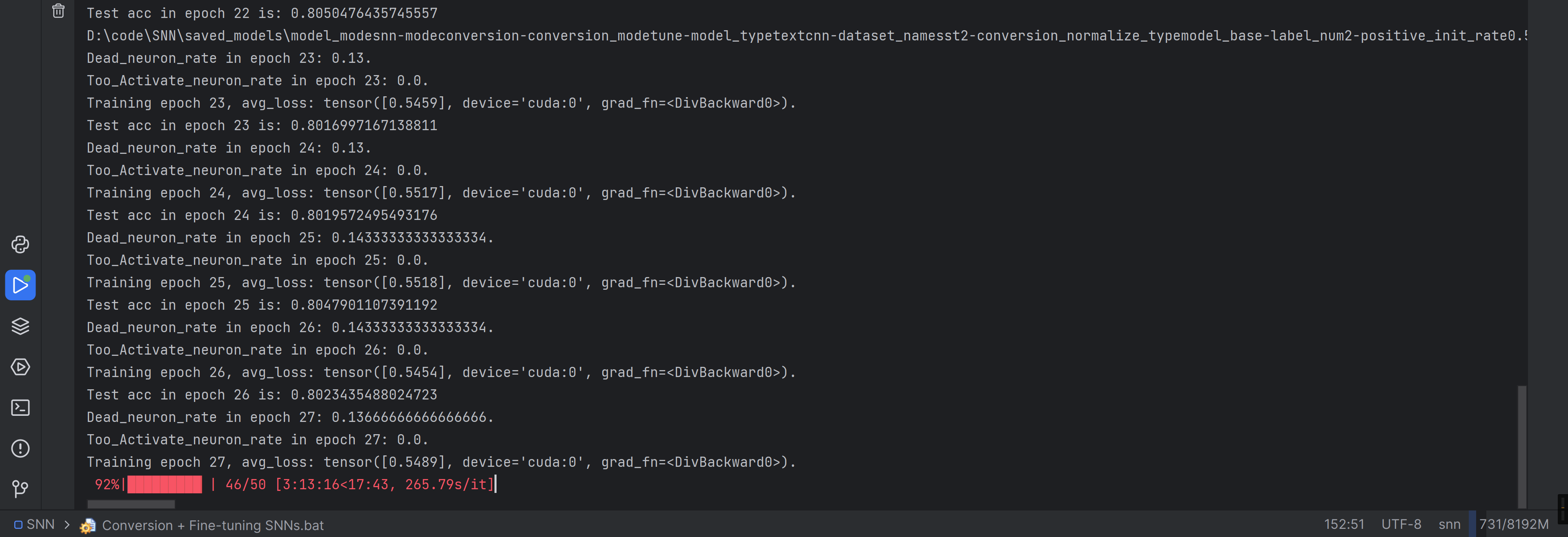
ohhhhhhhhhhhhhh终于跑完了
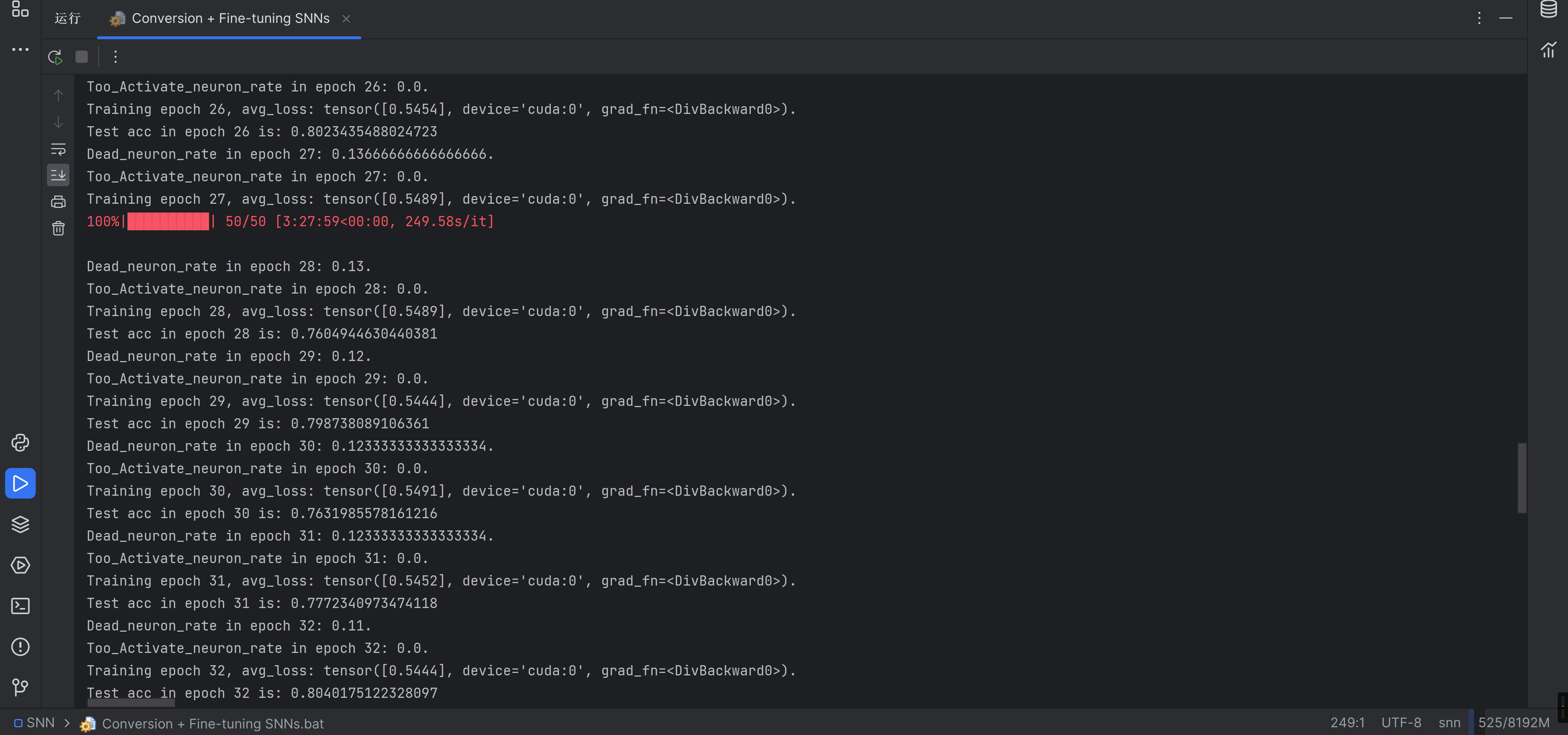
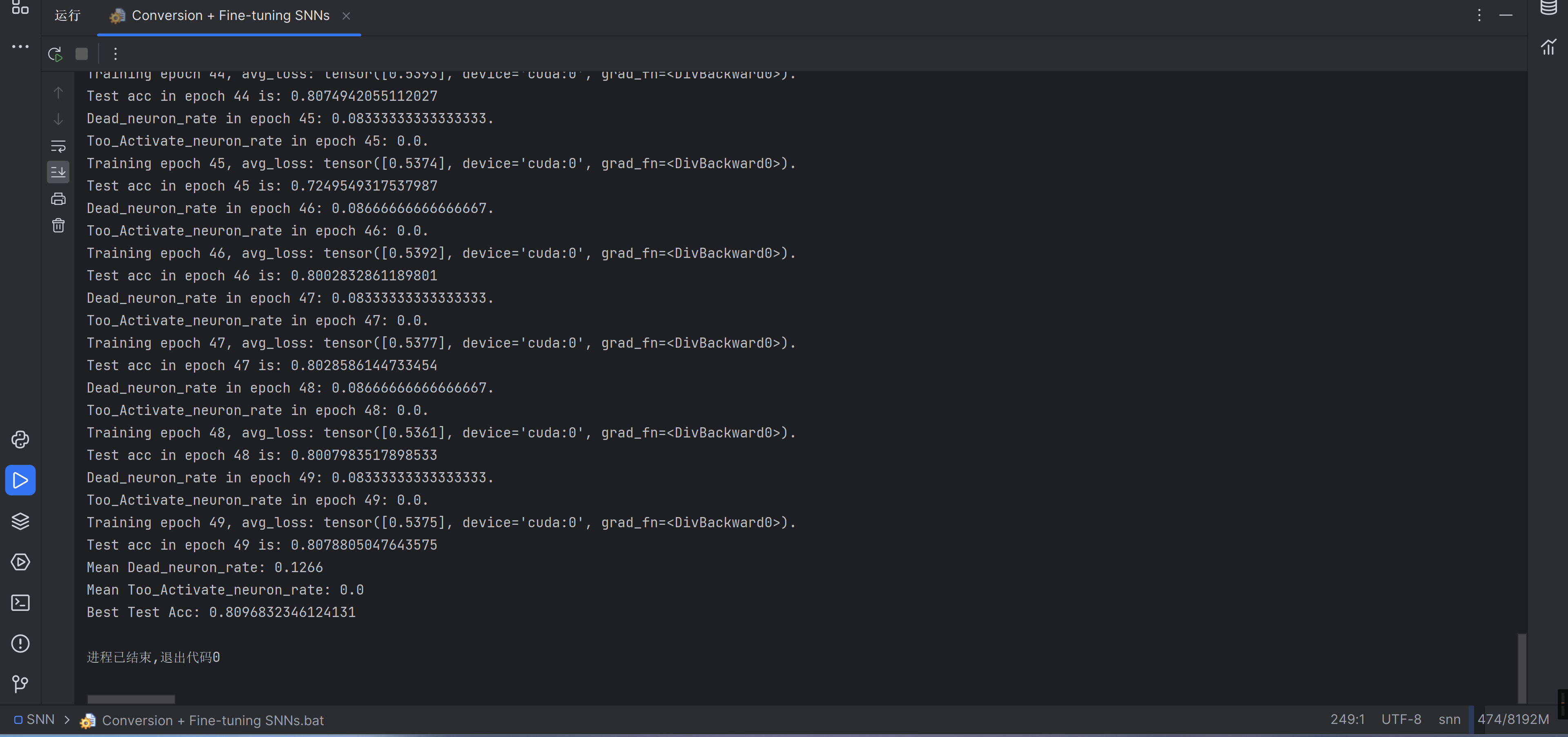
记录一下全部的输出
cmd.exe /c "Conversion + Fine-tuning SNNs.bat" |
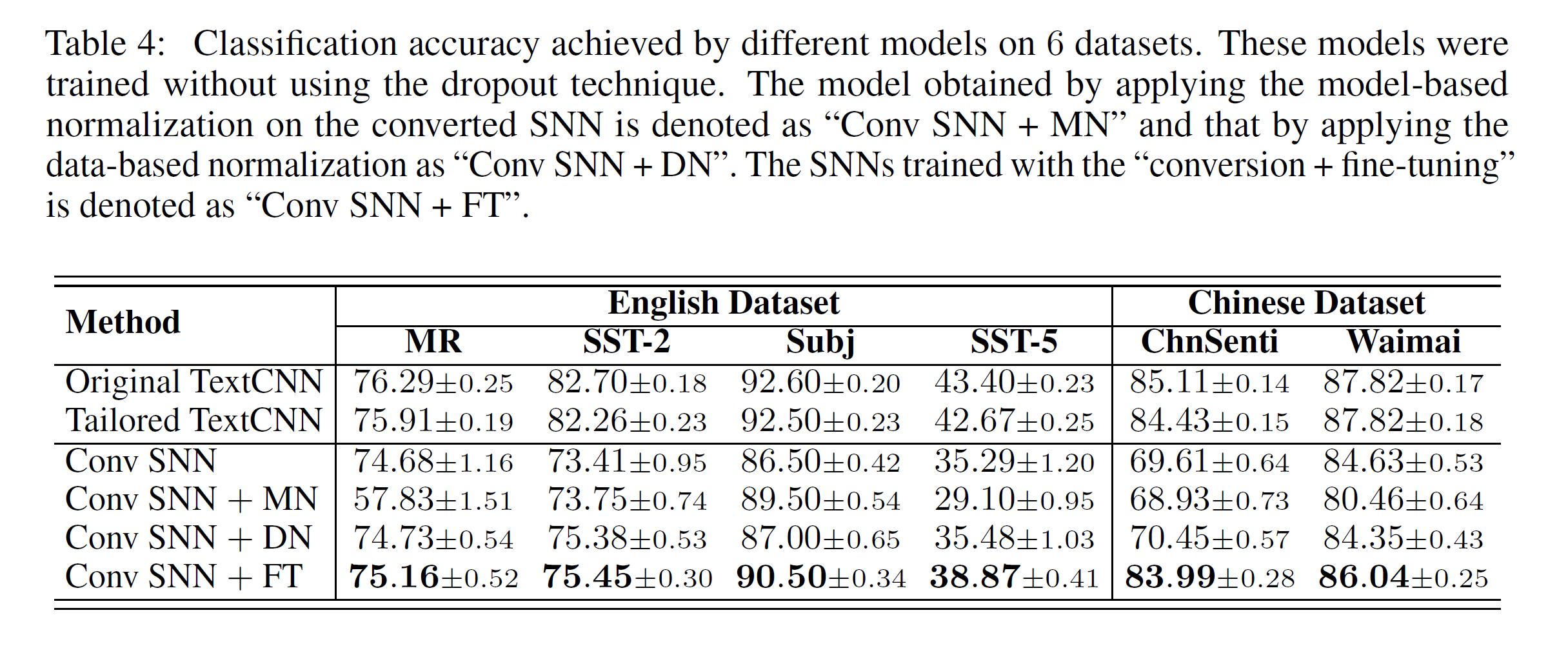
作者的结果如下,比作者的低一点
总结
历时20多天,终于把这个论文复现出来了。
再次感谢作者,提供了数据集!!!