
拼模型尝试
概述
记录一下自己首次组合模型的过程,希望可以为以后论文打基础。
PS:由于自己是零基础,看了一下李沐的教程,感觉理论部分有点多,没看完可能deadline都到了。唐老师的人工智能课也看了看,总感觉不是特别系统,都是一个一个项目,于是我打算效率亿点点,需要什么先学什么。
我需要跑的一个模型是这样的架构
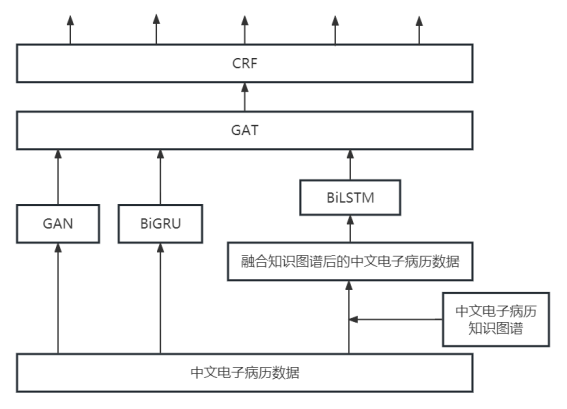
分析问题
客观分析一下我遇到的这个问题
1.目标问题
把这个架构跑通$\rightarrow$
从中文电子病历提取有用信息$\rightarrow$
进行医疗大数据挖掘、临床辅助决策系统、AI 电子病历质控系统构建等的基础工作
2.方法问题
寻找相似的项目或者使用了相似模型架构的项目,把他们的模型删删改改
删改可能需要借助到模型的官方文档,例如PaddleNLP文档,或者PyTorch文档
然后多借鉴一些博客的方法
3.执行问题
先安装一下paddle,然后尝试先把网上的项目跑通,在看懂的基础上进行修改
执行阶段
安装paddleNLP
# 默认前提是已经安装好了paddle(2.5.1),我之前已经安装完,现在直接进入这个环境(CUDA 11.0) |
验证安装
python |
没有error应该就是安装好了
复现别人项目
首先找到一个使用了类似框架的项目——中文命名实体识别-Bi-GRU+CRF,然后把代码以.py的格式下载下来,用PyCharm打开
打开后项目结构如下
开始一步一步跑了
首先遇到的一个问题,UnicodeDecodeError: 'gbk' codec can't decode byte 0xa8 in position 2: illegal multibyte sequence
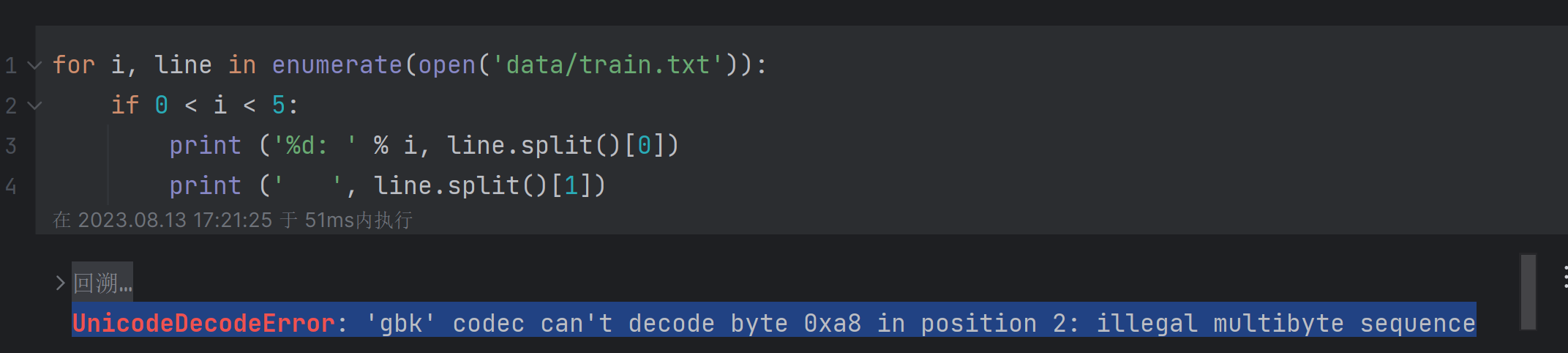
加一个encoding属性就可以了
for i, line in enumerate(open('data/train.txt',encoding='utf-8')): |
往下跑的时候又出现了一个错,ValueError: not enough values to unpack (expected 2, got 1)
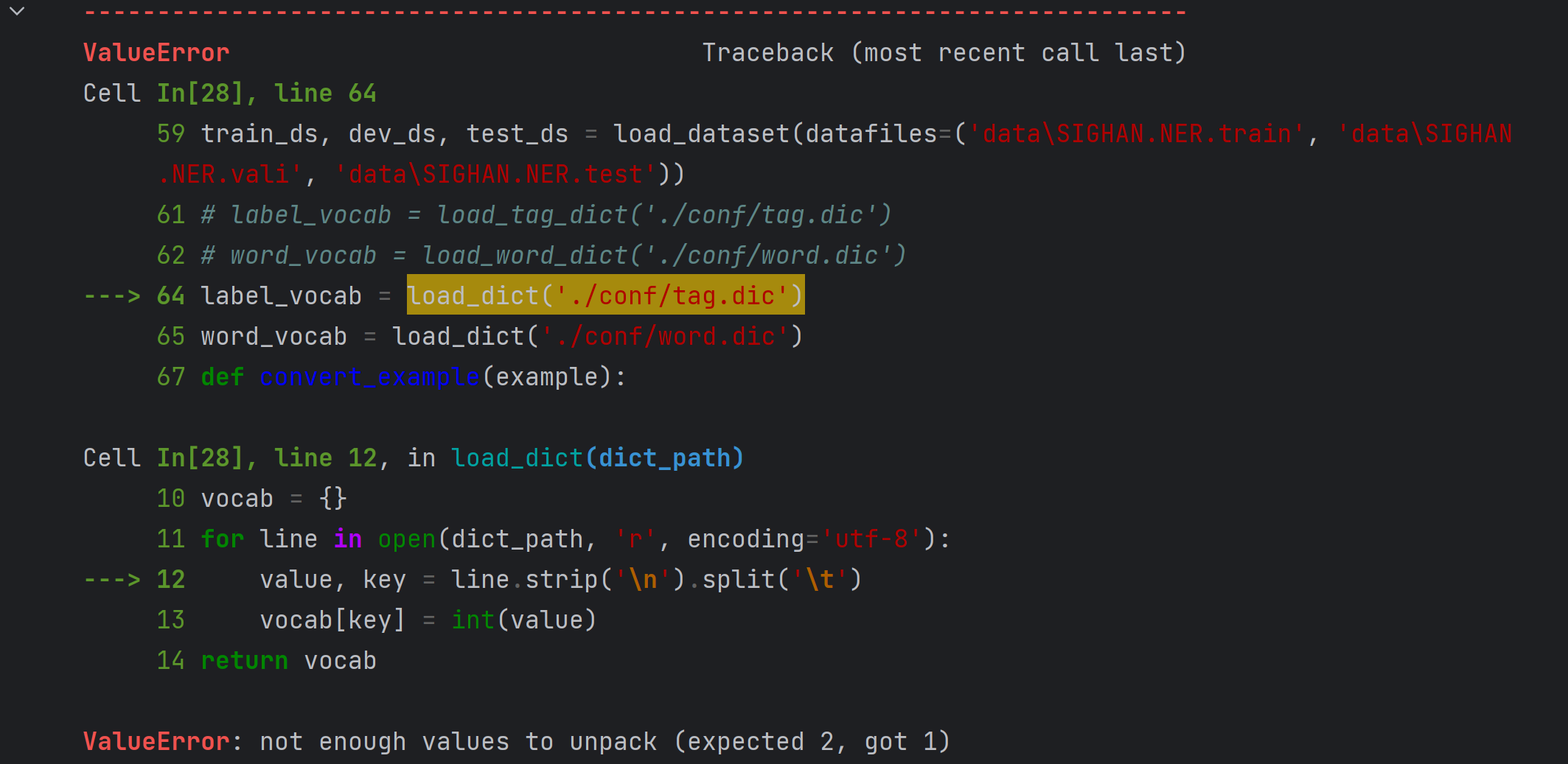
经过调试发现,word_vocab = load_dict('./conf/word.dic')这句就不会报错,只有前一句报错,于是我对比了两个数据集,发现了原因
word.dic数据集(部分)
0 a |
tag.dic数据集(部分)
B-PER |
问题就出现在函数load_dict的这句话上
def load_dict(dict_path): |
于是我分开写了两个函数
def load_word_dict(dict_path): |
后面的调用在改一下就行了
label_vocab = load_tag_dict('./conf/tag.dic') |
按照同样的逻辑,把前面单元格里的代码改一下就行,但是发现还有错误

发现上下两个代码块其实意思差不多,把上面代码块里的load_dataset函数替换掉下面的就行
def load_dataset(datafiles): |
之后好多代码块都没有报错,直到需要训练的时候,遇到了这个
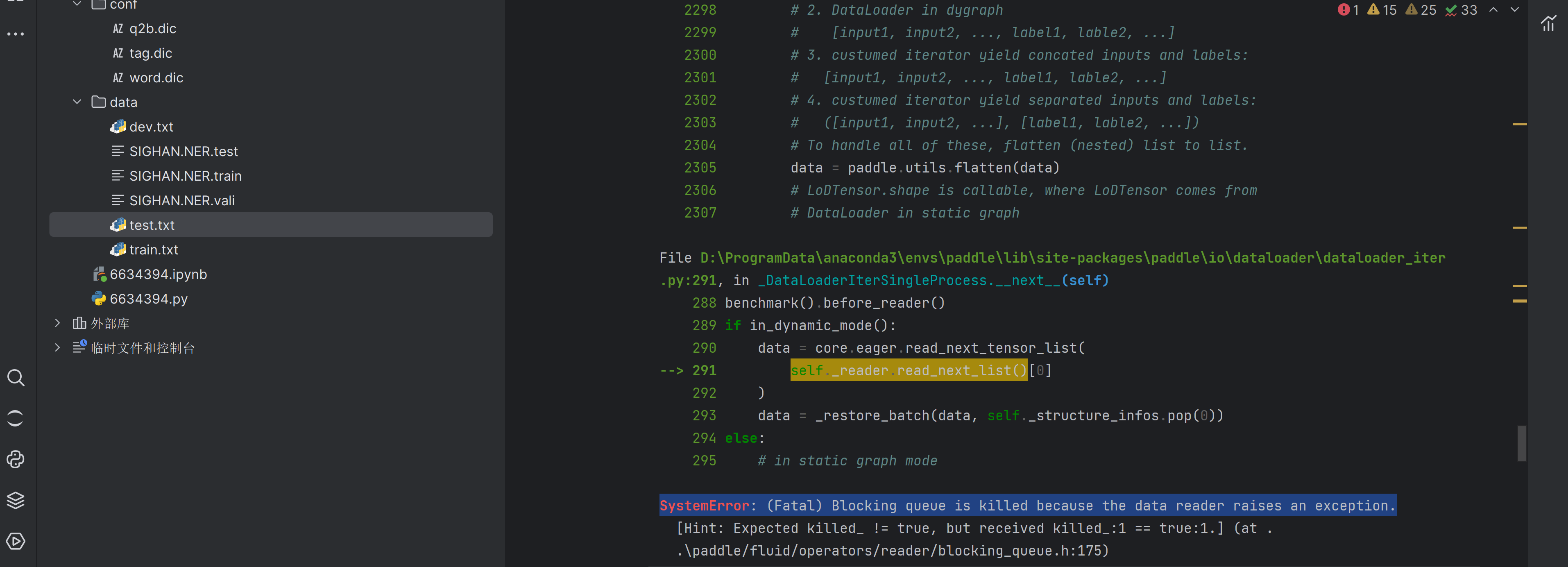
网上查了好长时间也不知道怎么解决,以为是版本paddle太高了,降级完但是出现了更多的错,弄了好半天也没成功,最后又装回2.5.1版本的了。后来看到网上说很可能是dataset类型的原因,官方API要求的类型如下
dataset (Dataset) - DataLoader 从此参数给定数据集中加载数据,此参数必须是 paddle.io.Dataset 或 paddle.io.IterableDataset 的一个子类实例。
而我的类型是paddlenlp.datasets.dataset.MapDataset
